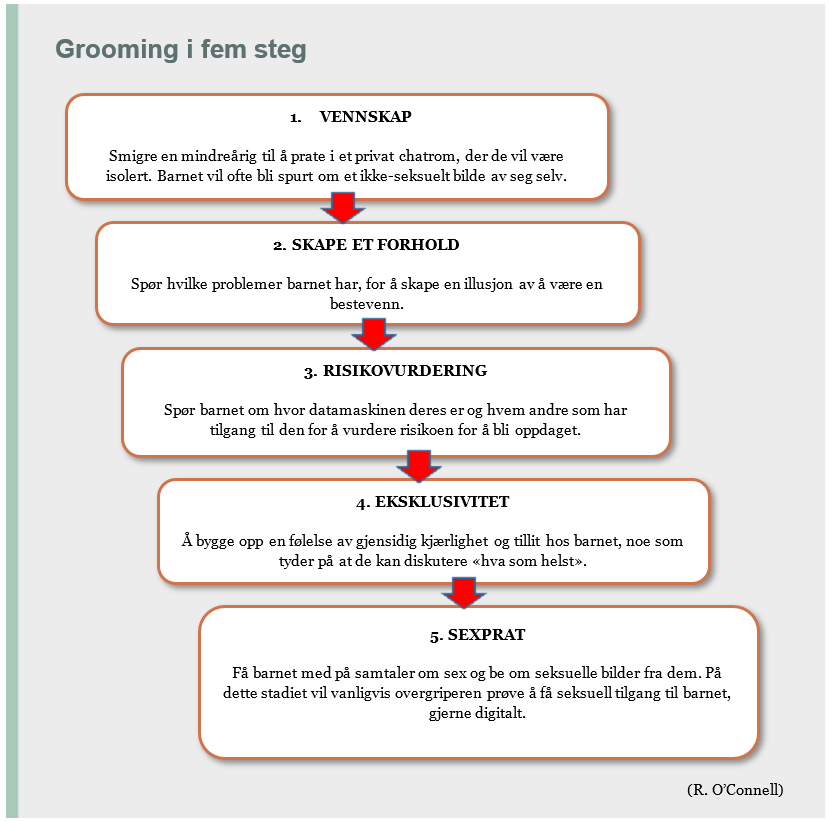
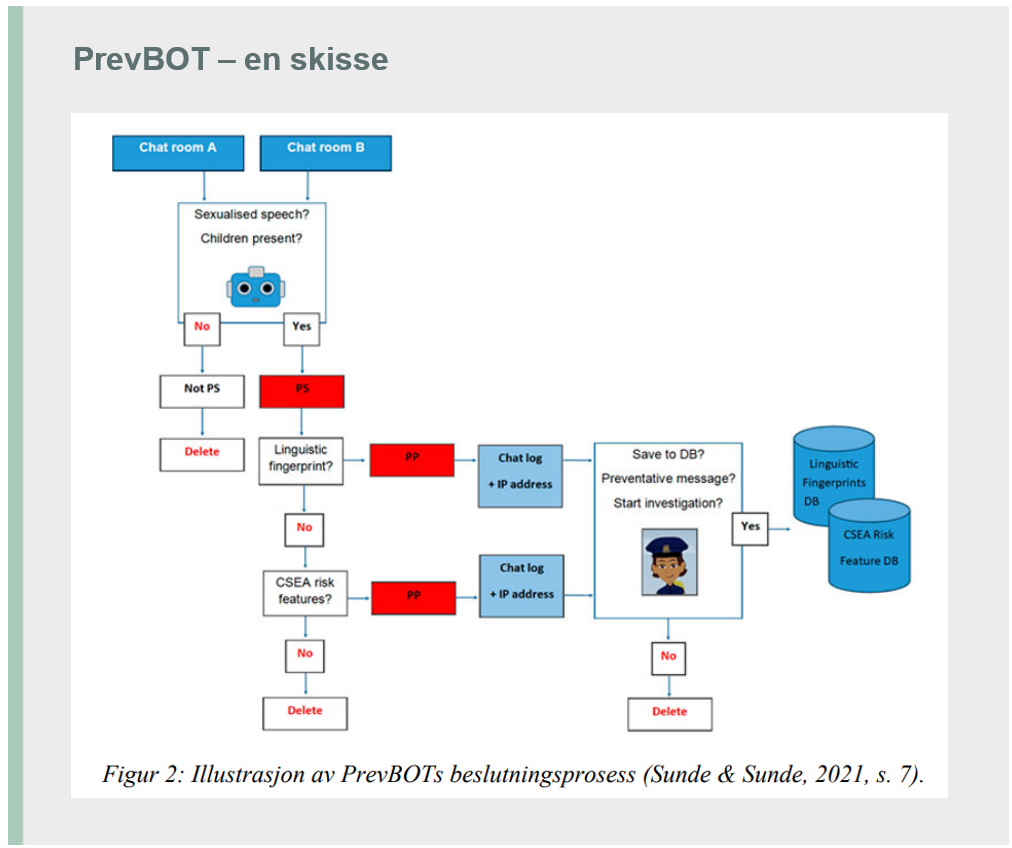
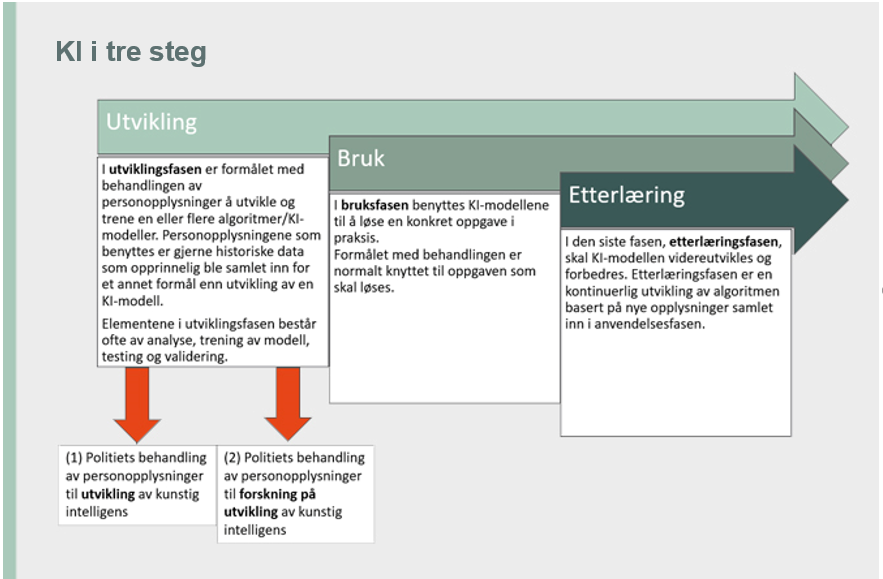
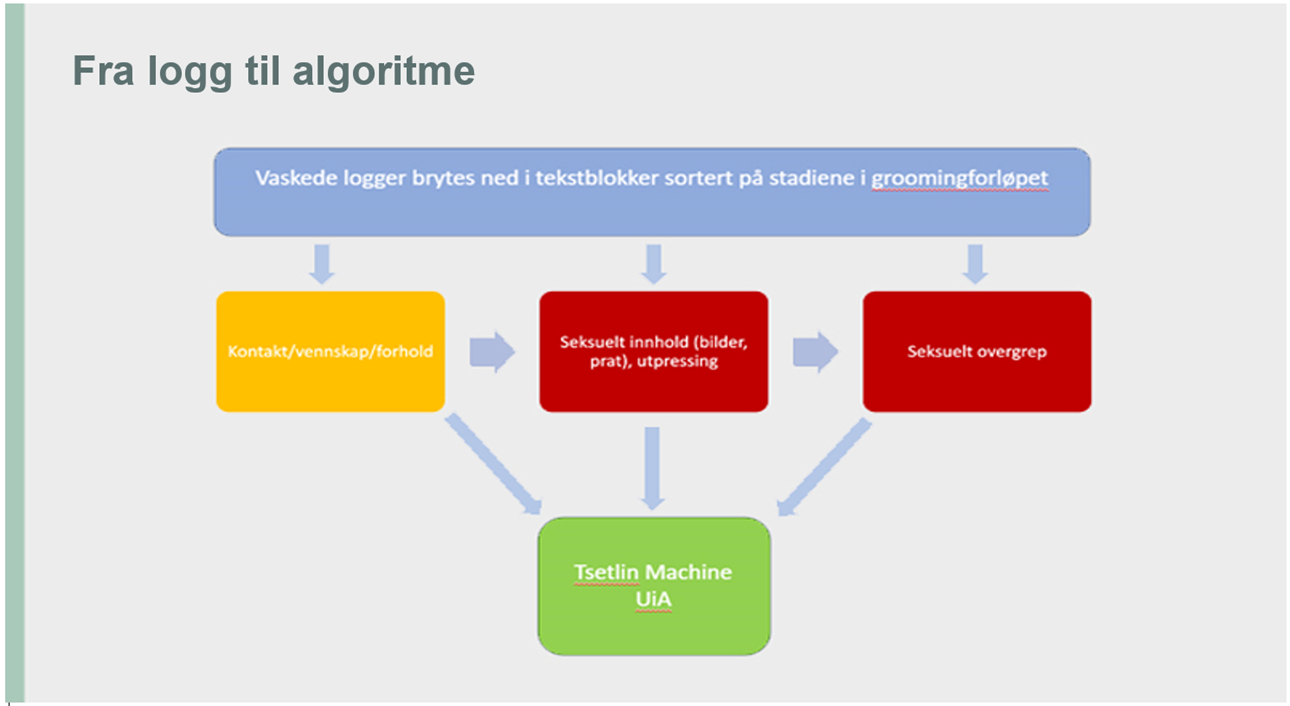
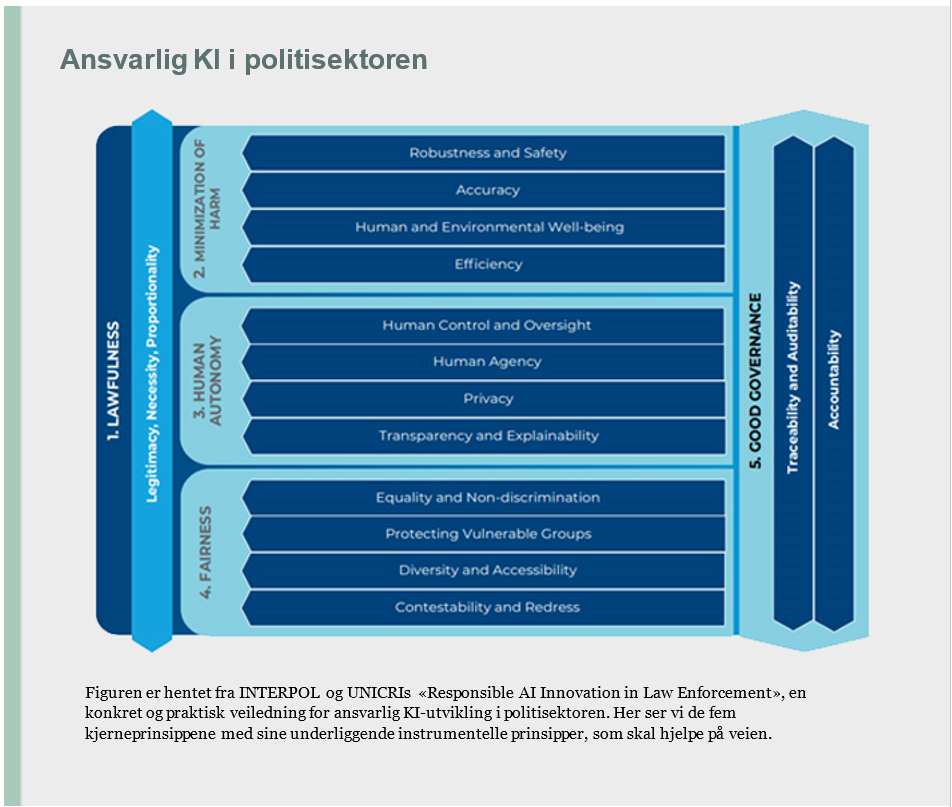
Hva er forskning?
Det fremgår av fortalepunkt 159 i personvernforordningen at «[N]år personopplysninger behandles i forbindelse med formål knyttet til vitenskapelig forskning, bør denne forordning også få anvendelse på slik behandling». Siden PrevBOT er et forskningsprosjekt, vil behandlingen av personopplysninger skje i forskningsøyemed. Det må først vurderes hvorvidt utviklingen av PrevBOT faller inn under forskningsbegrepet i personvernforordningen. Dette fordi behandling av personopplysninger med forskningsformål står i en særstilling i personvernforordningen, hvor visse unntak fra de generelle reglene gjelder.
Det eksisterer ingen universell og akseptert definisjon av begrepet «vitenskapelig forskning». Begrepet er heller ikke definert i personvernforordningen eller personopplysningsloven.
OECDs definisjon av forskning
OECD har satt følgende internasjonale retningslinjer for avgrensning og klassifisering av forskning:
Forskning og eksperimentell utvikling (FoU) er kreativt og systematisk arbeid som utføres for å oppnå økt kunnskap – herunder kunnskap om mennesket, kultur og samfunn – og for å utarbeide nye anvendelser av tilgjengelig kunnskap.
Hentet fra Frascati-manualen 2015 (s. 36) på forskningsradet.no (pdf)
Begrepet «vitenskapelig forskning» skal etter fortalepunkt 159 i personvernforordningen tolkes vidt og kan f.eks. omfatte teknologisk utvikling og demonstrasjon, grunnleggende forskning og anvendt forskning. Det bør nevnes at Personvernrådet for tiden arbeider med retningslinjer for behandling av personopplysninger til vitenskapelige formål, som antas å gi en oversikt over, samt tolkning, av de ulike bestemmelsene som regulerer forskning i forordningen.
PrevBOT er organisert som et forskningsprosjekt
PrevBOT-prosjektet ledes av PHS, som er en statlig høgskole. I tillegg til å være den sentrale utdanningsinstitusjonen for politiutdanning, driver PHS også med etter- og videreutdanning, masterutdanning og forskning innen politivitenskap. Som nevnt innledningsvis, er PrevBOT-prosjektet organisert som et forskningsprosjekt. Rammene for prosjektet er angitt i et prosjektnotat fra PHS levert til Justis- og beredskapsdepartementet.
Datatilsynet har ikke gjort noen selvstendig vurdering av om behandlingsaktivitetene i PrevBOT-prosjektet utgjør behandling av personopplysninger med forskningsformål, men legger i det videre til grunn PHS’s premiss om at selve utviklingen av PrevBOT i PHS’ regi anses som «vitenskapelig forskning» etter personvernforordningen.
Forskjell på utvikling (forskning) og bruk av PrevBOT
Datatilsynet vil fremheve at det er en forskjell på behandling av personopplysninger til forskning på utvikling av kunstig intelligens, og bruk av PrevBOT. Det er klart at selve bruken av PrevBOT faller utenfor forskningsdefinisjonen. Etter Datatilsynets syn, vil heller ikke etterlæring av en algoritme som er i bruk i alminnelighet anses som vitenskapelig forskning. Det er derfor viktig at de ansvarlige i PrevBOT-prosjektet er bevisste på hvor grensen mellom forskning og bruk går, slik at man ikke lener seg på forskningssporet i personvernregelverket når det kommer til bruk og etterlæring av løsningen.
Den behandlingsansvarlige i et forskningsprosjekt
Den behandlingsansvarlige er overordnet ansvarlig for å overholde personvernprinsippene og regelverket etter personvernforordningen, og det er denne som bestemmer formålet med behandlingen av personopplysninger og hvilke midler som skal benyttes, jf. personvernforordningen artikkel 4 nr. 7. I et forskningsprosjekt kan det være én eller flere behandlingsansvarlige (enten felles eller separate), og den behandlingsansvarlige skal blant annet påse at det foreligger behandlingsgrunnlag.
PrevBOT-prosjektet består av flere arbeidspakker med ulike aktører, og det er viktig at de(n) behandlingsansvarlige identifiseres. For Datatilsynet fremstår det slik at, i alle fall PHS anses som behandlingsansvarlig i PrevBOT-prosjektet. Hvis det er to eller flere behandlingsansvarlige, kan det være at det foreligger felles behandlingsansvar etter personvernforordningen artikkel 26. Dersom noen av aktørene anses som databehandlere, må det inngås en databehandleravtale med disse.
Om utlevering av personopplysninger fra politiet
Personopplysningene (chatloggene) i PrevBOT ble opprinnelig innsamlet av politiet med formål om å etterforske. Når politiet tilgjengeliggjør personopplysninger for behandling i PrevBOT-prosjektet, må politiet ha et rettslig grunnlag for denne tilgjengeliggjøringen. Vi har ikke tatt stilling til denne tilgjengeliggjøringen fra politiet, da denne behandlingsaktiviteten faller utenfor rammene for PrevBOT-prosjektet.
Vi vil likevel fremheve at forutsetningene som nevnt under kapittel 5, som gjelder «den som utleverer/tilgjengeliggjør personopplysninger», må være til på plass. Datatilsynet vil også knytte noen kommentarer til forenelighetsvurderingen, i kontekst av viderebehandling til bruk for forskning.
Forenlig viderebehandling
Forenelighetsvurderingen gjelder for opplysninger den behandlingsansvarlige allerede sitter på Når chatloggene blir tilgjengeliggjort for PrevBOT-prosjektet til bruk for forskning, anses dette som behandling av personopplysninger for «sekundære formål». Når vi sier «sekundære formål», tenker vi på typer av formål som direkte er angitt i forordningen – som blant annet inkluderer «formål knyttet til vitenskapelig forskning», jf. personvernforordningen artikkel 5 nr. 1 bokstav b . Forskning som sekundært formål anses som et forenelig formål, sml. artikkel 6 nr. 4 i personvernforordningen, forutsatt at nødvendige garantier i tråd med personvernforordningen artikkel 89 er på plass. Dette innebærer at personopplysningene kan behandles for dette formålet, såfremt slike garantier er tilstede.
Slik Datatilsynet ser det, vil behandlingsaktivitetene som angitt ovenfor ha de samme formålene, nemlig formål knyttet til vitenskapelig forskning. Det følger imidlertid av forarbeidene til personopplysningsloven at dersom viderebehandling for forskningsformål består i at opplysninger utleveres til andre behandlingsansvarlige, må den behandlingsansvarlige som mottar personopplysningene, kunne påvise et eget behandlingsgrunnlag.
Lovhjemmel for forskning
All bruk av personopplysninger må ha et behandlingsgrunnlag for å være lovlig. Personvernforordningen oppstiller ingen særskilte behandlingsgrunnlag for forskningsformål, hvilket betyr at man må se hen til de alminnelige behandlingsgrunnlagene i artikkel 6 i personvernforordningen. I forskningsøyemed kan flere behandlingsgrunnlag være aktuelle, men for PrevBOT-prosjektet anser Datatilsynet det særlig relevant å se hen til artikkel 6 nr. 1 bokstav e. Bestemmelsen dekker blant annet behandling av personopplysninger som er «nødvendig for å utføre en oppgave i allmennhetens interesse».
Forordningen gir ingen føringer for hva som er å anse som en oppgave i allmennhetens interesse. I den norske kommentarutgaven til forordningen legges det til grunn «at det ikke er opp til hvert enkelt land å definere hva som er en oppgave av allmenn interesse, men at det over tid vil utvikles en felles europeisk standard på dette området».
Kravet til nødvendighet setter rammene for hva som er en lovlig behandling av personopplysninger. Det er den konkrete behandlingen av personopplysninger som må være nødvendig for å utføre en oppgave i allmennhetens interesse. Relevante vurderingstema er blant annet om oppgaven i allmennhetens interesse kan oppfylles med en mindre inngripende behandling, og om behandlingen går lengre enn det oppgaven tilsier. Det europeiske personvernrådet (EDPB) har i sine retningslinjer uttalt følgende:
Assessing what is ‘necessary’ involves a combined, fact-based assessment of the processing “for the objective pursued and of whether it is less intrusive compared to other options for achieving the same goal”. If there are realistic, less intrusive alternatives, the processing is not ‘necessary’.
Datatilsynet anser det ikke nødvendig med en inngående vurdering her, da det synes ganske klart at behandlingen av personopplysninger innenfor rammene av PrevBOT-prosjektet oppfyller vilkårene i artikkel 6 nr. 1 bokstav e.
Behandling av særlige kategorier med personopplysninger
Artikkel 9 nr. 1 oppstiller et generelt forbud mot å behandle særlige kategorier av personopplysninger. Når særlige kategorier av personopplysninger behandles, må det for det første foreligge behandlingsgrunnlag etter personvernforordningen artikkel 6. I tillegg må ett av unntakene i artikkel 9 nr. 2 komme til anvendelse.
Opplysninger om en persons seksuelle forhold anses som en særlig kategori av personopplysninger etter personvernforordningen artikkel 9 nr. 1. Datatilsynet legger til grunn at dersom det først er tale om behandling av personopplysninger i PrevBOT-prosjektet, så vil disse fort falle inn under begrepet særlige kategorier i artikkel 9. Dersom særlige kategorier av personopplysninger behandles, vil det være aktuelt å se hen til artikkel 9 nr. 2 bokstav j i personvernforordningen.
Bestemmelsen stiller flere vilkår:
- Behandlingen er nødvendig for formål knyttet til vitenskapelig forskning i samsvar med personvernforordningen artikkel 89 nr. 1
- Det kreves supplerende rettsgrunnlag (se mer om dette nedenfor).
- Behandlingen må i tillegg stå i et rimelig forhold til det mål som ønskes oppnådd, den må være forenlig med det grunnleggende innholdet i retten til vern av personopplysninger og sikre egnende og særlige tiltak for å verne den registrertes grunnleggende rettigheter og interesser. Hvorvidt disse vilkårene er oppfylt, beror på en konkret vurdering.
Supplerende rettsgrunnlag
For behandling av personopplysninger etter artikkel 6 nr. 1 bokstav e og artikkel 9 nr. 2 bokstav j i personvernforordningen kreves det et supplerende rettsgrunnlag, hvilket betyr at grunnlaget for behandlingen i bestemmelsene «fastsettes» i unionsretten eller nasjonal rett. Det følger videre av artikkel 6 nr. 3 detaljerte krav til hvordan lovverket bør utformes, eksempelvis at formål bør angis, hvilke type opplysninger som registreres, berørte registrerte og regler for viderebehandling mv. Det må vurderes konkret hvor presist det supplerende rettsgrunnlaget må være.
Ved behandling av særlige kategorier med personopplysninger, vil legalitetsprinsippet slå sterkere inn, hvor det blant annet gradvis stilles strengere krav til utformingen av hjemmelen i det supplerende rettsgrunnlaget.
I kontekst av PrevBOT-prosjektet vil tre potensielle supplerende rettsgrunnlag presenteres.
1. Personopplysningsloven §§ 8 og 9
I norsk rett er det lite særregulering av forskning, utenom på helseforskningsområdet, og det finnes ingen konkrete forskningshjemler i politiregisterloven. Vi må derfor se hen til de alminnelige supplerende rettsgrunnlagene for forskning er nedfelt i §§ 8 og 9 i personopplysningsloven. Formålet med §§ 8 og 9 er å gi supplerende rettsgrunnlag for forskning der det ikke finnes annet supplerende rettsgrunnlag i særlovgivningen.
Bestemmelsen i § 8 oppstiller flere vilkår. For det første må det være snakk om formål knyttet til vitenskapelig forskning. Det vises til drøftelsen ovenfor, og Datatilsynet anser at behandlingen av personopplysninger som gjøres i PrevBOT oppfyller dette vilkåret.
Videre må behandlingen være nødvendig. I lovkommentaren på Juridika antas det at nødvendighetsvilkåret her ikke har noen selvstendig betydning, ved siden av nødvendighetsvilkåret i artikkel 6 nr. 1 bokstav e i personvernforordningen. Så lenge vilkåret er oppfylt i artikkel 6, så vil det være oppfylt etter § 8 i personopplysningsloven.
Personopplysningsloven § 8
Bestemmelsen gjelder for behandling av personopplysninger for formål knyttet til vitenskapelig forskning og angir at:
Personopplysninger kan behandles på grunnlag av personvernforordningen artikkel 6 nr. 1 bokstav e dersom det er nødvendig for (…) formål knyttet til vitenskapelig eller historisk forskning (…). Behandlingen skal være omfattet av nødvendige garantier i samsvar med personvernforordningen artikkel 89 nr. 1
Det oppstilles i tillegg et krav om at behandlingen er omfattet av nødvendige garantier i samsvar med personvernforordningen artikkel 89 nr. 1. Hva som ligger i «nødvendige garantier» fremgår ikke av forordningen, men bestemmelsen oppstiller eksempler på tiltak som kan iverksettes for å sikre den registrertes rettigheter og friheter. Det kreves blant annet at det er innført tekniske og organisatoriske tiltak for særlig å sikre at prinsippet om dataminimering overholdes. Slike tiltak kan omfatte pseudonymisering, kryptering, streng tilgangsstyring, slettefrister mv.
I PrevBOT-prosjektet er flere slike tiltak allerede iverksatt. Det vises eksempelvis til at det i PIT er begrenset hvem som vil ha tilgang til chatloggene etter at de tilgjengeliggjøres fra de lokale politidistriktene, og at chatloggene skal vaskes for personopplysninger før de tilgjengeliggjøres for CAIR/UiA. Datatilsynet oppfordrer likevel den behandlingsansvarlige til å vurdere om det er andre tiltak som kan være aktuelle, knyttet til de ulike behandlingsaktivitetene i prosjektet.
Dersom særlige kategorier av personopplysninger behandles i PrevBOT-prosjektet, så må de strengere vilkårene i § 9 være oppfylt. Etter § 9 stilles i tillegg et krav om at «samfunnets interesse i at behandlingen finner sted, klart overstiger ulempene for den enkelte».
Personopplysningsloven § 9
Bestemmelsen gjelder for behandling av særlige kategorier av personopplysninger for formål knyttet til vitenskapelig forskning og angir blant annet at:
Personopplysninger som nevnt i personvernforordningen artikkel 9 nr. 1 kan behandles uten samtykke fra den registrerte dersom behandlingen er nødvendig for (…) formål knyttet til vitenskapelig eller historisk forskning (…) og samfunnets interesse i at behandlingen finner sted, klart overstiger ulempene for den enkelte. Behandlingen skal være omfattet av nødvendige garantier i samsvar med personvernforordningen artikkel 89 nr. 1.
Det kan merkes at ordlyden «klart overstiger» tyder på at terskelen er høy, og det må foreligge klar interesseovervekt. Ordlyden er her noe annerledes enn ordlyden i artikkel 9 nr. 2 bokstav j, som angir at det må stå «i rimelig forhold til». Spørsmålet er altså om samfunnets interesse i at behandlingen av personopplysninger i PrevBOT-prosjektet finner sted klart overstiger ulempene for de registrerte som får personopplysningene sine behandlet i forskningen (her: den fornærmede, gjerningspersonen og eventuelle tredjepersoner som blir omtalt i chatloggene).
Det er klart at digitale overgrep ovenfor barn er alvorlig kriminelle handlinger, som av flere blir omtalt som et folkehelseproblem. Dette taler for at samfunnet har en klar interesse i at det forskes på muligheter for å forebygge slik kriminalitet, som PrevBOT. Samtidig må de konkrete ulempene for de registrerte vurderes konkret, særlig sett opp mot hvilke garantier som iverksettes for å begrense personvernulempene for den registrerte.
For behandling av personopplysninger etter personopplysningsloven § 9, må PHS først rådføre seg med personvernombudet eller annen som oppfyller kravene i personvernforordningen artikkel 37 nr. 5 og 6 og artikkel 38 nr. 3 første ledd og annet punktum, jf. § 9 annet ledd. Ved rådføringen skal det vurderes om behandlingen vil oppfylle kravene i personvernforordningen og øvrige bestemmelser fastsatt i eller med hjemmel i loven. Rådføringsplikten gjelder likevel ikke dersom det er utført en vurdering av personvernkonsekvenser etter personvernforordningen artikkel 35. Datatilsynet vil her fremheve at alle vurderinger av personvernkonsekvenser (DPIA’er) skal forelegges Personvernombudet, slik at det alltid vil være en vurdering til grunn.
På generelt grunnlag mener Datatilsynet at bestemmelsene i §§ 8 og 9 er noe uklare sammenlignet med kravene som stilles til hvor presist det supplerende rettsgrunnlaget skal være. En svakhet ved § 9 er at det blir opptil personvernombudet e.a. å foreta en intern vurdering for å klarere om man har lov til å forske. Derfor mener Datatilsynet at store offentlige myndigheter bør ha egne forskningshjemler i særlovgivningen som tydelig angir rammene for forskningen.
Oppsummert så kan behandling av personopplysninger PrevBOT-prosjektet oppfylle kravet om supplerende rettsgrunnlag, så lenge vilkårene i personopplysningsloven § 8 (og § 9 hvis særlige kategorier behandles), jf. artikkel 6 nr. 1 bokstav e (og artikkel 9 nr. 1 bokstav j hvis særlige kategorier behandles), er oppfylt.
2. Vedtak etter politiregisterloven
Det finnes ingen konkret hjemmel i politiregisterloven for å utføre forskning med grunnlag i straffesaksdata. Adgangen til å oppheve taushetsplikten i politiregisterloven § 33 for opplysninger brukt til forskning, gir ikke i seg selv et rettsgrunnlag for å behandle dataene i forskningen. Det følger av § 33 nr. 2 at beslutningskompetansen for opphevelse av taushetsplikt for straffesaker er lagt til riksadvokaten.
På helseforskningsområdet har departementet i forarbeidene til personopplysningsloven lagt til grunn at lovhjemlede vedtak om dispensasjon eller unntak fra taushetsplikten vil kunne gi supplerende rettsgrunnlag etter artikkel 6 nr. 3.
Politiregisterloven § 33 nr. 1
Når det finnes rimelig og ikke medfører uforholdmessig ulempe for andre interesser, kan det bestemmes at opplysninger i det enkelte tilfelle gis til bruk for forskning, uten hinder av taushetsplikten i § 23.
Siden politiregisterloven har en tilsvarende bestemmelse om dispensasjon fra taushetsplikt til forskning, så kan det stilles spørsmål ved om et vedtak etter politiregisterloven § 33 kan utgjøre et supplerende rettsgrunnlag etter artikkel 6 nr. 3 i personvernforordningen. Dette beror på en konkret vurdering av hvorvidt grunnlaget for vedtaket er tydelig nok, sammenholdt med hvilken behandling som utføres. Jo mer inngripende behandlingen er, desto klarere må det supplerende rettsgrunnlaget være.
Riksadvokaten samtykket i brev 27. juli 2021 til at en spesialetterforsker ved Trøndelag politidistrikt ble gitt tilgang til chatlogger i straffesaker om seksuelle overgrep mot barn, jf. politiregisterloven § 33. Dispensasjonen fra taushetsplikt gjaldt Nettprat-prosjektet, som lå forut for PrevBOT-prosjektet, og prosjektet har senere fått riksadvokatens samtykke til å overføre relevante chatlogger til PIT i forbindelse med PrevBOT-prosjektet.
På den ene siden, kan det argumenteres for at når et utenforliggende offentlig organ, slik som Riksadvokaten, beslutter at taushetsplikten kan oppheves i forskningsøyemed, så vil det være med på å gi noen garantier for behandlingen av personopplysningene. Riksadvokaten kan eksempelvis i vedtaket kreve at visse tiltak iverksettes for å sikre den registrertes rettigheter og friheter ved behandlingen, etter en vurdering og avveining av behandlingens nytte og konsekvensene for de registrerte. I tillegg følger det av politiregisterloven § 33 at bestemmelsen er avgrenset til tilfeller som gjelder forskning. Bestemmelsen som vedtaket er hjemlet i avgrenser derfor til en gruppe med formål som opplysningene kan brukes til (forskning).
På den annen side, kan man – gjennom uttalelsene i forarbeidene til personopplysningsloven – argumentere for at lovgivers vurdering er spesifikk for helseforskningsfeltet. Datatilsynet er ikke kjent med at lovgiver har uttalt seg på samme måte når det gjelder politiregisterloven § 33, selv om departementet i nevnte forarbeider anerkjenner at «behandling også kan skje på andre grunnlag, for eksempel unntak eller dispensasjonsvedtak etter andre bestemmelser». Hvorvidt denne uttalelsen kun referer seg til unntak/vedtak på helseområdet, eller også har overføringsverdi til andre områder, er usikkert.
Et annet poeng er at helseforskning er underlagt en forholdsvis streng lov, helseforskningsloven. Det samme er ikke tilfellet for annen forskning, hvor det ofte kun er de generelle reglene i personvernregelverket, og forskningsetikken for øvrig, som setter rammene for behandlingen av personopplysningene.
Det foreligger altså flere for- og motargumenterer for at vedtak etter politiregisterloven § 33 kan utgjøre et supplerende rettsgrunnlag etter artikkel 6 nr. 3 og artikkel 9 nr. 2 bokstav j i personvernforordningen.
3. Ny lovhjemmel
Det kan stilles spørsmål om en eventuell utvidelse av politiregisterlovens virkeområde, til å omfatte behandling av opplysninger ved utvikling av kunstig intelligens til politimessige formål, vil gjøre at slik behandling dermed kun reguleres av politiregisterloven. Datatilsynet stiller seg tvilende til om en eventuell forskrifts- eller lovendring vil kunne føre til at behandlingen faller utenfor personvernforordningens virkeområde. En slik endring, vil trolig ikke, etter Datatilsynets syn, påvirke unntaket i personvernforordningen artikkel 2 nr. 2 bokstav d.
Derimot kan en lovbestemmelse/forskrift i særlovgivningen kunne gi et supplerende grunnlag etter personvernforordningen. Da må imidlertid hjemmelen utformes med dette for øyet, slik at man oppfyller kravene i artikkel 6 nr. 2 og nr. 3.
Særlig om behandling av personopplysninger om straffedommer og lovovertredelser
Opplysninger om straffedommer og lovovertredelser er ikke å regne som særlige kategorier av personopplysninger, men behandling av slike opplysninger omtales særskilt i personopplysningsloven § 11 og personvernforordningen artikkel 10. Det er naturlig å tolke «straffedommer og lovovertredelser» etter disse bestemmelsene til å omfatte opplysninger som knyttes til en konkret dom, men også opplysninger om kriminelle handlinger hvor det ikke foreligger dom på behandlingstidspunktet.
Behandling av slike opplysninger er underlagt visse begrensninger; dette følger av artikkel 10 i personvernforordningen. Nærmere bestemt kan slike opplysninger kun behandles under en offentlig myndighets kontroll, eller hvis behandlingen gjøres av private såfremt det foreligger behandlingsgrunnlag i personvernforordningen artikkel 6 og et supplerende rettsgrunnlag.
Det kan diskuteres om PHS som forskningsinstitusjon er underlagt offentlig myndighets kontroll, men det vil likevel kunne foreligge supplerende rettsgrunnlag personopplysningsloven § 11. Bestemmelsen åpner på en kronglete måte for behandling til forskning uten samtykke dersom samfunnets interesse i at behandlingen finner sted klart overstiger ulempene for den enkelte, ved at den viser til personopplysningsloven § 9.
For behandling etter personopplysningsloven § 11, må PHS først rådføre seg med personvernombudet om behandlingen vil oppfylle kravene i personvernforordningen og øvrige bestemmelser fastsatt i eller med hjemmel i loven. Rådføringsplikten gjelder likevel ikke dersom det er utført en vurdering av personvernkonsekvenser etter personvernforordningen artikkel 35.
Oppsummering
Som en oppsummering, finnes det flere bestemmelser i personvernforordningen som, på gitte vilkår, gir adgang til å behandle personopplysninger med formål knyttet til vitenskapelig forskning, inkludert særlige kategorier og personopplysninger om straffedommer og lovovertredelser.
Hvilke rettigheter har de registrerte når deres personopplysninger blir brukt til forskning?
Den registrerte har flere rettigheter etter personvernregelverket når dennes personopplysninger behandles. Personvernforordningen har imidlertid noen spesifikke bestemmelser som gjør seg gjeldende når personopplysninger behandles for formål knyttet til vitenskapelig forskning. Disse spesifikke bestemmelsene fremgår av personopplysningsloven § 17, og gjør innskrenkninger i de generelle rettighetene til den registrerte. Disse innskrenkingene er kun er anvendelige såfremt det foreligger tilstrekkelige garantier etter personvernforordningen artikkel 89 nr. 1.
Vi vil i det følgende ta for oss noen sentrale rettigheter ved utlevering og behandling av personopplysninger for forskning:
- Retten til informasjon gir den registrerte blant annet rett til informasjon om hvem som mottar personopplysninger, hvem den behandlingsansvarlige er, formålet og det rettslige grunnlaget for behandlingen, med mindre dette vil være umulig eller kreve en uforholdsmessig innsats, jf. personvernforordningen artikkel 14 nr. 1, 2 og nr. 5 bokstav b. Her må det foretas en avveining av inngrepet overfor den enkelte og hensynet til forskningsprosjektet. Det vil være sterke hensyn som tilsier informasjonsplikt på grunn av opplysningenes karakter og det faktum at hverken fornærmede, gjerningsperson eller tredjeperson har avgitt opplysningene frivillig. Hvis det anses umulig eller vil kreve en uforholdsmessig innsats å informere, skal den behandlingsansvarlige treffe egnede tiltak for å verne den registrertes rettigheter og friheter og berettigede interesser, herunder gjøre informasjonen offentlig tilgjengelig.
- Retten til innsyn etter personvernforordningen artikkel 15 gjelder ikke for slik behandling dersom det vil kreve en uforholdsmessig stor innsats å gi innsyn, eller innsynsretten sannsynligvis vil gjøre det umulig eller i alvorlig grad hindre at målene med behandlingen nås, jf. personopplysningsloven § 17 første ledd. Dette unntaket gjelder ikke dersom behandlingen får rettsvirkninger eller direkte faktiske virkninger for den registrerte. Dersom retten til innsyn foreligger for den konkrete behandlingen, er det viktig å ta med dette ved utformingen av algoritmen/KI-modellen.
- For retten til sletting og begrensning av behandling etter artikkel 16 og 18 i personvernforordningen, så må det i forskningsdesignet tas høyde for to tilfeller: rett til sletting av treningsdataene og rett til sletting fra den trente modellen hvis den inneholder personopplysninger. I forskningstilfeller vil retten til retting/begrensning ikke gjelde etter personopplysningsloven § 17 annet ledd hvis rettighetene sannsynligvis vil gjøre det umulig eller i alvorlig grad hindre at målene med behandlingen nås. Dette beror på en konkret vurdering.
- Retten til å protestere på behandlingen gjelder ikke dersom behandlingen av personopplysninger til vitenskapelige formål gjøres i medhold av artikkel 6 nr. 1 bokstav e i personvernforordningen, jf. artikkel 21 nr. 6.