Teknologi: Tsetlin-maskinen
Politihøgskolen ser for seg å bygge PrevBOT på Tsetlin-maskin (TM). Styrken til en TM, er at den skal være bedre på forklarbarhet enn nevrale nettverk. I et prosjekt som PrevBOT, der mennesker skal bli kategorisert som potensielle overgripere basert på (i de fleste tilfeller) lovlig kommunikasjon på åpent nett, vil det være viktig å kunne forstå hvorfor verktøyet konkluderer som det gjør.
Tsetlin maskin er en maskinlæringsalgoritme først designet av den norske forskeren Ole-Christoffer Granmo i 2018. Granmo er professor i informatikk ved UiA, og har senere videreutviklet Tsetlin-maskinen med kollegaer. Siden det er en relativt ny metode innen maskinlæring, pågår det fortsatt forsking på området med mål om å utforske og optimalisere dens anvendelse og ytelsesevne. Som enhver maskinlæringsmodell, er Tsetlin-maskinen avhengig av kvaliteten og representativiteten til treningsdataene.
Tsetlin-maskiner
Tsetlin-maskinen er ikke en type nevrale nettverk. Det er en algoritme basert på prinsipper fra forsterkningslæring og setningslogikk (også kalt proposisjonslogikk). Algoritmen egner seg for oppgaver innen klassifisering og beslutningstaking der både tolkbarhet og nøyaktighet er viktig. Setningslogikk er en algebraisk metode som klassifiserer setninger eller utsagn som sanne eller falske, ved hjelp av logiske operasjoner som «og, eller, ikke, hvis, da».
For å lære bruker Tsetlin-maskinen forsterkningslæring og lærende automat. Forsterkningslæring gjør at modellen belønnes eller straffes basert på resultatet av utførte handlinger, mens den lærende automaten tar beslutninger basert på tidligere erfaringer, og disse erfaringene fungerer som retningslinjer for nåværende handlinger.
Tsetlin-maskinen bruker klausuler for å forstå hvordan individuelle klausuler påvirker beslutningsprosessen. Denne tilnærmingen gjør Tsetlin-maskinen egnet for bruksområder der tolkbarhet er viktig.
Tsetlin-maskiner vs. nevrale nettverk
Nevrale nettverk (dyplæringsmodeller) krever store datasett og store beregningsressurser for trening. Tsetlin-maskinen trenger færre beregningsressurser sammenlignet med komplekse nevrale nettverk. Forskning fra 2020 viser at Tsetlin-maskinen er mer energieffektiv, ved at den bruker 5,8 ganger mindre energi enn nevrale nettverk.
Nevrale nettverk egner seg for oppgaver som prediksjon og bilde- og talegjenkjenning, identifisering av komplekse mønstre og relasjoner i data. Tsetlin-maskinen egner seg for visse typer klassifiseringsproblemer der tolkbarhet er viktig. Tsetlin-maskinen bruker setningslogikk for beslutningstaking. Den består av en samling Tsetlin-automater som representerer logiske regler. Hver Tsetlin-automat har en vektet beslutning som blir justert basert på læringsprosessen. Vektingen styrer i hvilken grad en spesifikk egenskap eller mønster påvirker beslutningen. Dette skal gi høyere grad av forståelse fordi bruken av logiske regler gjør at beslutninger kan spores tilbake til de enkelte klausulene.
Nevrale nettverk er inspirert av den menneskelige hjernen og består av mange lag med kunstige nevroner som er sammenkoblet gjennom mange noder og vekter. De er ofte komplekse og lite transparente, og ansett som «svarte bokser» på grunn av kompleksiteten og begrenset forståelse av hvordan de tar beslutninger.
Nevrale nettverk kan også utilsiktet forsterke og opprettholde skjevheter som finnes i treningsdataene. Hvis treningsdataen inneholder partisk eller diskriminerende informasjon, kan modellen lære og reprodusere slike skjevheter i dens genererte utdata. Dette kan føre til utilsiktede konsekvenser og forsterke fordommer.
På grunn av Tsetlin-maskinens transparens kan den undersøkes for skjevhet og denne kan muligens fjernes fra modellen ved å modifisere setningslogikken, i stedet for indirekte endringer fra datasiden eller via ettertrening. Dette indikerer at den er lettere å korrigere.
Tsetlin-maskinen lærer å assosiere ord med konsepter og bruker ord i logisk form for å forstå konseptet. En viktig komponent i denne prosessen er bruken av konjunktive klausuler, som er setninger eller uttrykk som kombinerer to eller flere betingelser som er tilstede eller fraværende i inngangsdataene for å kunne klassifiseres som sanne eller falske.
Et eksempel er: «jeg vil dra på stranden bare hvis det er sol og hvis jeg får fri fra jobb». Her representerer «hvis det er sol» og «hvis jeg får fri fra jobb» konjunktive klausuler som må oppfylles samtidig for at personen skal ta beslutningen om å dra på stranden. Disse klausulene brukes til å identifisere mønstre i inndata, ved å skape betingelser som må oppfylles samtidig. Videre brukes disse klausulene til å bygge opp beslutningsregler som danner grunnlaget for klassifisering. Evnen til å håndtere sammensatte betingelser gjør Tsetlin-maskinen egnet for å avgjøre om inndata tilhører en spesifikk klasse eller ikke.
Arbeidsflyten til Tsetlin-maskinen i PrevBOT-prosjektet
I PrevBOT tas det sikte på å utvikle en transparent språkmodell som kan klassifisere tilstedeværelsen av grooming i en samtale. Det første steget er å gi algoritmen generell opplæring i det norske språket. Dette gir algortimen en solid forståelse av språket, og reduserer påvirkningen av potensielt begrensende datasett i groomingspråkopplæringen. Hvis vi begrenser opplæringen til dette smale emnet, risikerer vi å ha for få eksempler tilgjengelige. En annen vesentlig grunn er at en generell forståelse av et språk legger grunnlaget for å utvikle spesialiserte ferdigheter på en mer helhetlig måte. For å trene algortimen i å beherske det norske språket generelt, er bruk av store norske datasett hensiktsmessig (Språkbanken ved Nasjonalbiblioteket tilbyr dette). Dette kan også sammenlignes med forhåndstrening i store språkmodeller.
Norsk grooming
Erfaringer fra norske straffesaker viser at overgriper og barn kommuniserer på norsk. Teknologien må følgelig baseres på norske tekstdata. En forutsetning for realisering er derfor at det må finnes tilstrekkelig mengde norske tekstdata til å kunne utvikle KI-modellen. På tidspunktet for sandkasseprosjektet er det usikkert om denne forutsetningen er oppfylt, men den vil kunne realiseres over tid, gitt at metoden er formålstjenlig.
Når algoritmens språkkunnskaper har nådd et tilstrekkelig nivå, kommer man til det andre trinnet: å lære den opp til å bli spesialist innen groomingspråkklassifisering. Etter å ha oppnådd grunnleggende norskkunnskaper, kan algortimen deretter lære ordkonteksten og relevansen til hvert ord innenfor groomingspråket. På denne måten, før man tar fatt på den spesifikke oppgaven med grooming-deteksjon, vil algortimen være i stand til å beherske språket på et generelt nivå.
På dette stadiet spiller teksten i chatloggene fra straffesakene en viktig rolle. Eksemplene må være svært spesifikke og presisise, og det skal merkes av en erfaren domeneekspert innen grooming. På bakgrunn av den generelle opplæringen i det norske spåket, sammen med kunnskapen om grooming språkklassifisering, vil algoritmen da kunne være i stand til å gjenkjenne groomingsamtaler på norsk. Nedenfor gir vi en mer teknisk beskrivelse av trinn en og to.
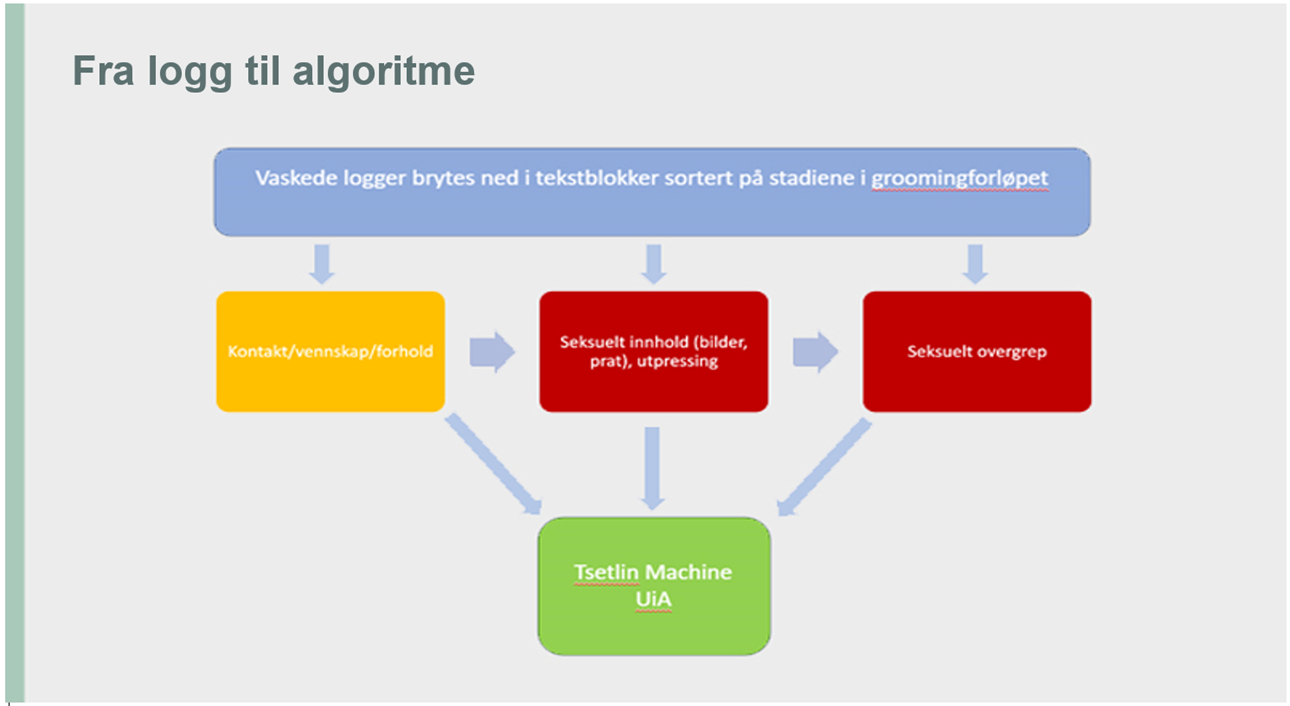
Første trinn: trene algoritmen i norsk
Først må de utvikle Tsetlin maskin-baserte autoenkodere som autonomt utfører ordinnbygging i store norske datasett. Treningen består i å produsere representasjoner for ord, og dette gjøres ved å basere seg på store datasett.
Tsetlin-maskinen bruker prinsipper fra setningslogikk og logiske klausuler for å ta beslutninger. Figuren under viser et eksempel på resultatene (pilene) av setningslogikk-innbygging ved bruk av Tsetlin-maskinen i et lite engelsk datasett. Tsetlin-maskinen bruker disse klausulene til å bygge opp beslutningsregler som danner grunnlaget for klassifisering.
Som illustrert, viser resultatene at ordene er korrelert med andre ord gjennom klausuler. Tar vi ordet «heart» som et eksempel, ser vi at det er relatert til «woman» og «love», samtidig som det også knyttes til «went» og «hospital». Dette eksempelet viser at ordet har ulike betydninger avhengig av konteksten. Det indikerer at Tsetlin-maskin-innbygging har kapasitet til å lære og etablere fornuftige korrelasjoner mellom ordene. Det er blant annet disse egenskapene som legger grunnlaget for bedre forklarbarhet og kanskje også manuelle justeringer.

Andre trinn: klassifisere grooming-språk
Treningsdataen må inneholde eksempler på tekst som er merket med enten grooming eller ikke-grooming. Utvalg av relevante regler, enten det er spesifikke ord, fraser eller struktur i teksten, er avgjørende for å gi algoritmen nødvendig informasjon. Algoritmen identifiserer grooming-samtaler ved å analysere språket og gjenkjenne mønstre eller indikatorer som er assosiert med risiko for grooming. Positive eksempler (grooming) og negative eksempler (ikke-grooming) brukes til å justere vektingen av klausulene.
Eksemplene skal i teorien være en integrert del av reglene til algoritmen og brukes under treningen for å hjelpe algoritmen med å forstå hva som kjennetegner grooming-samtaler. Treningsdataen som inneholder eksempler/tekster som er merket som grooming eller ikke-grooming blir altså brukt som en del av treningsprosessen. De brukes til å utvikle og justere reglene som algoritmen bruker til å identifisere grooming-samtaler. Når algoritmen trener, analyserer den de merkede eksemplene for å lære mønstre og indikatorer knyttet til grooming. Ved å sammenligne egenskapene ved positive (grooming) og negative (ikke-grooming) eksempler, justerer algoritmen gradvis vektingen av reglene eller klausulene den bruker til klassifisering. Det kan innebære å gi større vekt til ord eller setningsstrukturer som er assosiert med grooming, og mindre vekt til de som ikke er det. Ordinnbyggingen fra det første trinnet kan brukes til klassifisering.
Kombinasjonen av veiledet læring og forsterkningslæring innebærer gjentagende justering av de konjunktive klausulene. Justeringen foregår vanligvis automatisk og er basert på tidligere beslutninger. Under trening lærer algoritmen å tilpasse vektene for å gjenkjenne mønstre og gjøre riktige klassifiseringer. Det forventes at en ferdig opplært modell ikke bare kan klassifisere tekst som en potensiell grooming-samtale eller ikke, men at den også tolkes på grunn av algoritmens transparente natur. Tolkningen oppnås fra klausuler i en trent Tsetlin maskin-modell. Klausulene består av logiske regler som effektivt beskriver om språket er grooming eller ikke. For en gitt inndata-setning kan reglene hentes fra klausulene som er aktivert. Reglene kan deretter brukes for å forklare algoritmens beslutning.
Forenklet oversikt
-
Datainnhenting
Samle inn norsk tekst fra åpne norske kilder (Nasjonalbiblioteket) og chatlogger fra straffesaker (grooming-samtaler mellom potensielle ofre og potensielle overgripere) for å danne datasett. Datasettene bør inneholde varierte eksempler med både positive eksempler (grooming-samtaler) og negative eksempler (ikke-grooming). -
Dataforberedelse
Strukturering av data slik at den egner seg for Tsetlin-maskinen, f.eks. representere tekstdata ved hjelp av vektorrepresentasjoner (vektorisering av ord). Bag-of-word (BOW)-representasjoner (binarisering av ord) kan også brukes. -
Mål
Identifisere relevante egenskaper i tekst som skiller mellom grooming og ikke-grooming samtaler, for eksempel bruk av spesifikke ord, kontekstuelle nyanser/ledetråder, setningsstrukturer eller emosjonelle tonefall som er typiske for grooming-adferd. -
Trening
Strukturert data brukes til trening. Under treningen justerer Tsetlin-automatene sine interne paramatere for å gjenkjenne mønstre som er karakteristiske for grooming-samtaler. Dette innebærer å tilpasse logiske regler som tar hensyn til ordvalg, kontekst og andre relevante faktorer, spesifikke ord, utrykk eller mønstre assosiert med grooming -
Beslutningstaking
Etter trening skal algoritmen være i stand til å analysere og ta beslutninger om hvorvidt tekstdata inneholder indikasjoner på grooming. -
Tilbakemelding og finjustering
Resultatene vurderes for å redusere falskt positiver og negativer. Modellen justeres periodisk basert på tilbakemeldinger for å forbedre nøyaktigheten over tid. Dette kan omfatte nye data, finjustering av regler eller introduksjon av nye regler for å håndtere endrede mønstre. -
Implementering
Sanntidsdeteksjon for å varsle når det mistenkes grooming-mønstre. Tsetlin-maskinen gir utslag basert på sannsynligheten for at en nettsamtale inneholder elementer av grooming.