Innholdet i rettferdighetsprinsippet er dynamisk, som betyr at det endrer seg over tid i takt med samfunnsoppfatningen. Det Europeiske personvernrådet (EDPB) presiserer i sin veileder om innebygd personvern at rettferdighetsprinsippet omfatter ikke-diskriminering, den registrertes forventninger, behandlingens bredere etiske problemstillinger og respekt for den registrertes rettigheter og friheter. Rettferdighetsprinsippet har, med andre ord, et vidt anvendelsesområde.
Se EDPBs veileder om innebygd personvern (engelsk)
En tilsvarende beskrivelse finnes i fortalen til personvernforordningen, som uttrykker at prinsippet innebærer at all behandling av personopplysninger skal gjøres med respekt for den registrertes rettigheter og innenfor den registrertes rimelige forventninger om hva opplysningene skal brukes til. Åpenhet og transparens i behandlingen av personopplysninger henger altså nøye sammen med kravet til rettferdighet. Tilstrekkelig informasjon er avgjørende for at behandlingen skal være forutsigbar for den registrerte og for å kunne ivareta sin rett til rettferdig behandling av sine personopplysninger. Denne sluttrapporten vil ikke gå nærmere inn på problemstillinger knyttet til kravet til informasjon, men henviser til sluttrapporten til sandkasseprosjektet til Helse Bergen som har redegjort for dette tema.
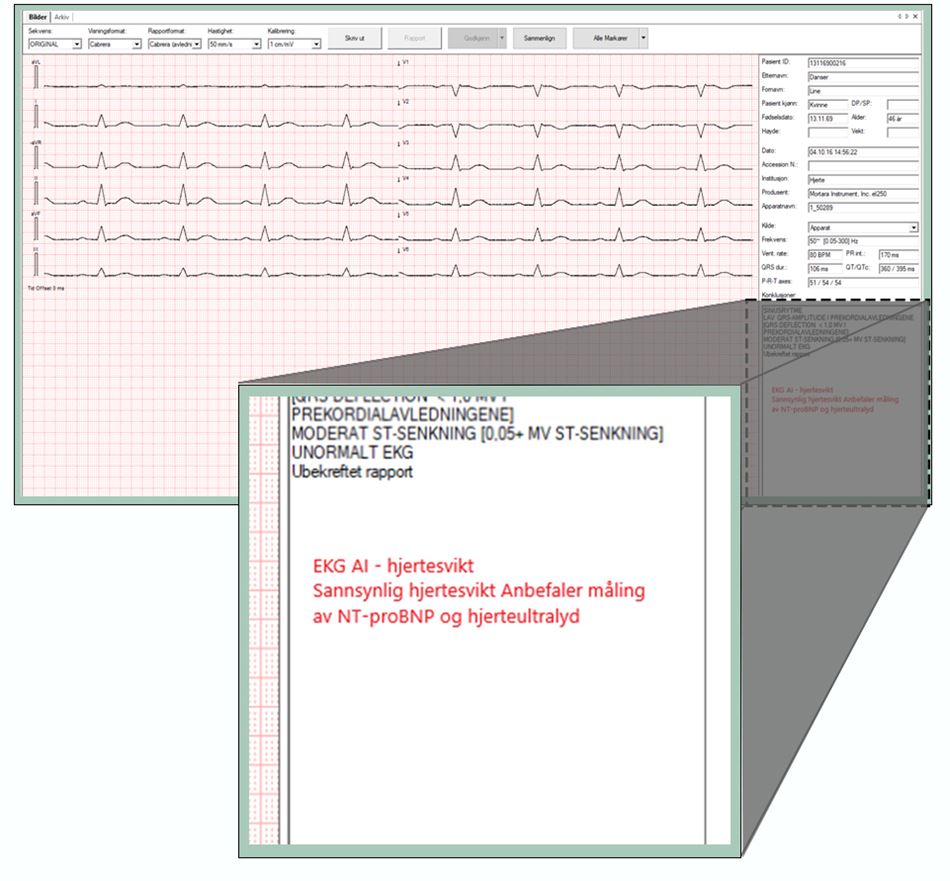
Fortalen til personvernforordningen uttrykker videre at den behandlingsansvarlige skal forhindre forskjellsbehandling av den enkelte på grunnlag av rasemessig eller etnisk opprinnelse, politisk oppfatning, religion eller filosofisk overbevisning, fagforeningsmedlemskap, genetisk status, helsetilstand eller seksuell orientering. Fortalen er ikke juridisk bindende, men kan benyttes som veiledende i tolkning av rettsreglene i personvernforordningen. I Ahus-prosjektet har vi blant annet stilt spørsmål ved hvorvidt EKG AI-algoritmen vil gi alle pasienter lik tilgang, og like god helsehjelp, uavhengig av om pasienten er mann eller kvinne, eller har en annen etnisk bakgrunn enn den etniske majoriteten av pasientene.
Rettferdighetsprinsippet står sentralt i flere andre lovverk, blant annet ulike menneskerettighetsbestemmelser og likestillings- og diskrimineringsloven (ldl.). Disse regelverkene får betydning for tolkning av begrepet rettferdighet, der kravene i noen tilfeller kan være strengere og mer spesifikke enn personvernregelverket.
Hva sier likestillings- og diskrimineringsloven?
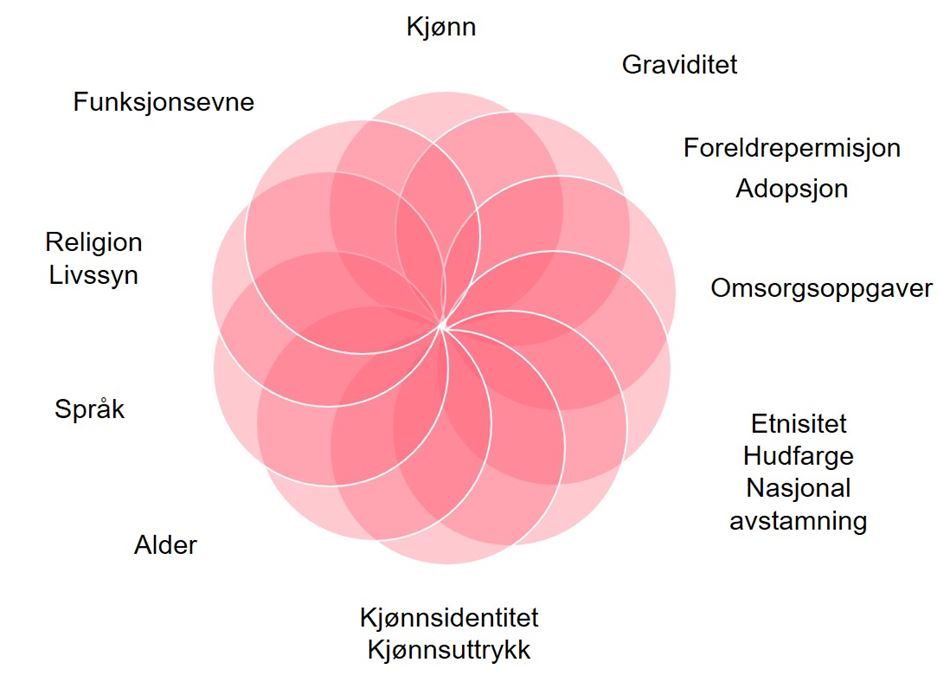
Likestillings- og diskrimineringsloven (ldl.) forbyr diskriminering på grunn av «kjønn, graviditet, permisjon ved fødsel eller adopsjon, omsorgsoppgaver, etnisitet, religion, livssyn, funksjonsnedsettelse, seksuell orientering, kjønnsidentitet, kjønnsuttrykk, alder eller kombinasjoner av disse grunnlagene», jf. § 6.
Definisjon av etnisitet:
Det følger av bestemmelsen at med «etnisitet» menes blant annet nasjonal opprinnelse, avstamning, hudfarge og språk.
Diskriminering defineres som usaklig forskjellsbehandling og kan forekomme «direkte» eller «indirekte», se henholdsvis ldl. §§ 7 og 8.
Direkte forskjellsbehandling betyr at personer med diskrimineringsvern behandles dårligere enn andre sammenlignbare personer, jf. § 7, mens indirekte forskjellsbehandling betyr at en tilsynelatende nøytral bestemmelse eller praksis fører til at personer med diskrimineringsvern stilles dårligere enn andre, jf. § 8. Indirekte diskriminering kan for eksempel oppstå ved at en tilsynelatende nøytral algoritme benyttes ukritisk på alle pasientgrupper. Som følge av at forekomsten av hjertesvikt har vært gjennomgående høyere blant menn enn kvinner, vil kvinnelige hjertesviktpasienter i mindre grad være representert i datagrunnlaget som kan gi kvinner mindre treffsikre prediksjoner.
Les mer om kjønnsstatistikk for hjertesvikt i Hjerte- og karregisterets rapport for 2012–2016 på fhi.no (pdf)
Både direkte og indirekte diskriminering krever årsakssammenheng mellom forskjellsbehandlingen og diskrimineringsgrunnlaget, altså at en person stilles dårligere på grunn av vedkommende kjønn, alder, funksjonsnedsettelse, etnisitet og ligenende.
Offentlige myndigheter har videre en aktivitetsplikt i ldl. § 24 til å arbeide aktivt, målrettet og planmessig for å fremme likestilling og hindre diskriminering. Arbeidet i sandkassa kan benyttes som et eksempel på et prosjekt som har til hensikt å fremme likestilling og forhindre diskriminering gjennom konkrete tiltak i offentlig helsetjeneste.
Rettferdighet som etisk prinsipp
Rettferdighet er også et etisk prinsipp, som innebærer at etiske vurderinger står sentralt i både tolkning av, og anvendelse av rettferdighetsprinsippet i personvernforordningen. I «Etiske retningslinjer for pålitelig kunstig intelligens» utarbeidet av en ekspertgruppe oppnevnt av EU-kommisjonen, nevnes det tre hovedprinsipper for ansvarlig kunstig intelligens, nemlig lovlig, etisk og sikker kunstig intelligens. De samme prinsippene gjenspeiles i regjeringens Nasjonale strategi for kunstig intelligens fra 2020.
I etikken reiser man spørsmål om hvordan man burde oppføre seg og handle for å minimere de etiske konsekvensene som kan oppstå ved bruk av kunstig intelligens. Selv om noe er innenfor loven i rettslig forstand, kan man likevel spørre seg om det er etisk riktig å utføre handlingen. Etiske refleksjoner burde stilles i alle faser av en algoritmes liv, henholdsvis i utviklingsfasen, når algoritmen brukes i praksis og i etterlæringsfasen.
I etikken ønsker man å besvare spørsmål som «hva er bra og dårlig, godt og ondt, riktig og galt eller rettferdig og lik behandling for alle?». En etisk tilnærming til EKG AI-prosjektet vil være å stille seg spørsmål om hvorvidt algoritmen gir like gode prediksjoner for alle pasienter. Ved økt bruk av algoritmer i klinisk behandling i fremtiden, vil det være relevant å stille spørsmål om de generelle fordelene kunstig intelligens bringer med seg kommer alle pasienter til gode.
Algoritmeskjevhet
Kunstig intelligens
Kunstig intelligens ble i Regjeringens nasjonale strategi for kunstig intelligens definert som «systemer som utfører handlinger, fysisk eller digitalt, basert på tolkning og behandling av strukturerte eller ustrukturerte data, i den hensikt å oppnå et gitt mål. Enkelte KI-systemer kan også tilpasse seg gjennom å analysere og ta hensyn til hvordan tidligere handlinger har påvirket omgivelsene.» Begrepet algoritme brukes ofte om programkode i et system, det vil si oppskriften på hva systemet skal finne løsningen på.
Løsninger som er basert på en programkode vil, naturlig nok, inneholde feil eller unøyaktigheter. Dette gjelder både for svært avanserte systemer og for enkle løsninger, men jo mer omfattende koden er, jo større er sjansen for feil. I maskinlæringsløsninger vil feilene vanligvis føre til at prediksjonen algoritmen gir, blir mindre nøyaktig eller gir galt resultat. En feil som systematisk gir mindre nøyaktige, eller gale, prediksjoner for enkelte grupper vil være eksempel på det vi kaller en algoritmeskjevhet.
Når to pasienter har et tilnærmet likt helsebehov, skal disse få like omfattende helsehjelp – uavhengig av etnisitet, kjønn, funksjonsnedsettelse, seksuell orientering og lignende. Hvis en algoritme derimot anbefaler at de skal motta ulik grad av bistand, kan det være grunn til å mistenke en form for diskriminering.
Det finnes mange mulige årsaker til algoritmeskjevhet og årsakene er ofte sammensatte. I dette prosjektet har vi konsentrert oss om fire årsaker til algoritmeskjevhet. Begrunnelsen er at disse fire årsakene har vært mest aktuelle for vårt prosjekt, men er også vanlige for kunstig intelligens generelt. Beskrivelsen og illustrasjonen nedenfor baserer seg på en fremstilling i «British medical journal», som har et særlig fokus på algoritmeskjevhet i helsesektoren. Vi ønsker å understreke at flere av årsakene kan føre til samme skjevhet, og at det eksisterer en overlapp mellom de forskjellige årsakene.
Les gjerne artikkelen "Bias in AI" på aimultiple.com
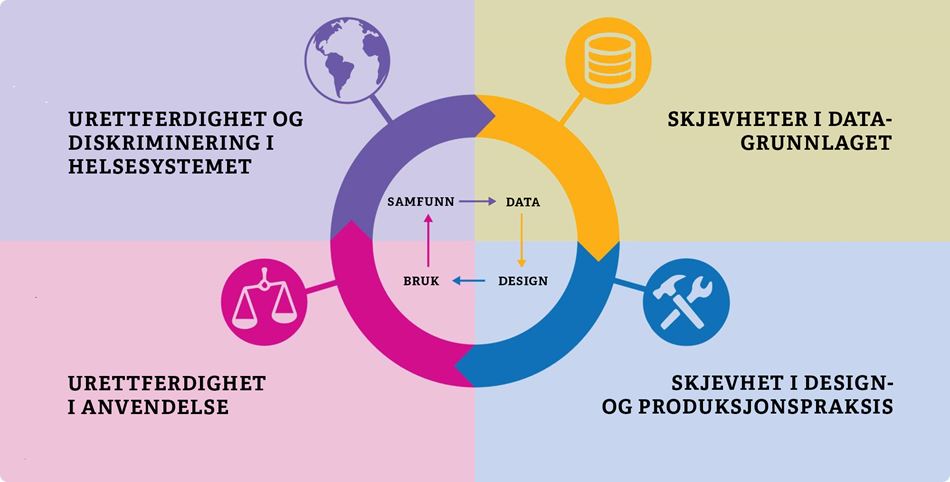
1 Urettferdighet og diskriminering i helsevesenet
En maskinlæringsalgoritme lager prediksjoner basert på statistisk sannsynlighet for visse utfall. Statistikken vil basere seg på historiske data som gjenspeiler virkeligheten, herunder eksisterende urettferdighet og diskriminering i helsevesenet. Det kan være snakk om ekskluderende systemer, helsepersonell med fordommer eller ulik tilgang til helsehjelp. Dette videreføres og forsterkes i algoritmen.
2 Skjevheter i datagrunnlaget
Urettferdighet i samfunnet vil gjenspeile seg i datagrunnlaget som tilføres algoritmen under trening. Dersom det foreligger skjevheter i faktagrunnlaget vil også algoritmens prediksjoner gjenspeile disse skjevhetene. Har man ikke et representativt mangfold i treningsdataene vil ikke algoritmen være i stand til å gi presise prediksjoner for underrepresenterte individer eller grupper. Dette kan eksempelvis oppstå ved at ulike befolkningsgrupper har ulik tilgang til helsehjelp av sosioøkonomiske årsaker.
3 Skjevhet i design- og produksjonspraksis
Skjevheter i algoritmen kan også springe ut av utviklernes fordommer og valg som tas underveis i utviklingen. En begrunnelse kan være at utviklerne har manglende kompetanse om, eller forståelse for, mulige diskriminerende utfall av designvalgene de gjør. En annen mulighet er at det ikke eksisterer systemer for å fange opp utilsiktet diskriminering når algoritmen benyttes i praksis.
4 Urettferdighet i anvendelse
En algoritme som inneholder skjulte skjevheter vil forsterke en allerede diskriminerende praksis. I tilfeller der algoritmen lærer av egne prediksjoner, vil skjevheten forsterkes ytterligere i algoritmen. Bruk av en algoritme som er programert med feil formål vil også kunne føre til diskriminering i praksis, eksempelvis at formålet om å avdekke en persons helsebehov begrunnes med hvor mye penger personen har brukt på helsetjenester.