I sandkasseprosjektet med Simplifai har vi utforsket handlingsrommet for bruk av personopplysninger i et beslutningsstøtteverktøy basert på maskinlæring.
Personvernforordningen skal gjelde på samme måte i 30 land i Europa. I tillegg har Norge spesialregler om personvern, blant annet i arbeidslivet. Disse spesialreglene er gitt i forskrifter til arbeidsmiljøloven og er ment å beskytte arbeidstakere mot unødvendig inngripende overvåking eller kontroll.
Hvordan gikk vi fram i vurderingen?
Sandkasseprosjektet drøftet i starten om vi skulle ta utgangspunkt i en full automatisering av DAM, eller DAM som beslutningsstøtte. Selv om automatisering vil gi størst effekt, er også risikoen for brudd på personvernreglene høyere, ved at innhold fra personlige e-postkasser blir sendt rett til offentlig journal. Prosjektet besluttet å fokusere på DAM som beslutningsstøtte.
Prosjektet gjennomførte to workshops med lovlighet som tema. Som forberedelse til samlingene, hadde Simplifai gjort rede for tekniske løsninger og formålene med de ulike modulene eller «botene» i løsningen. I tillegg ga NVE sitt syn på bl.a. formålene med de ulike behandlingene i modulene og hvilket rettslig grunnlag direktoratet så for seg for å ta løsningen i bruk. Ut fra dette grundige forarbeidet, skisserte Datatilsynet rammer for bruk, etterlæring og mulige tiltak for å gjøre DAM mer personvernvennlig.
Vi valgte å dele spørsmålet om rettslig grunnlag inn i faser: (1) bruksfasen, der algoritmemodellen brukes i saksbehandlingen og (2) etterlæringsfasen, der algoritmemodellen blir forbedret.
Simplifai kom til sandkassa med et utviklet verktøy. Prosjektet avgrenset mot spørsmålet om Simplifai hadde rettslig grunnlag for å utvikle DAM.
Rettslig grunnlag for bruksfasen
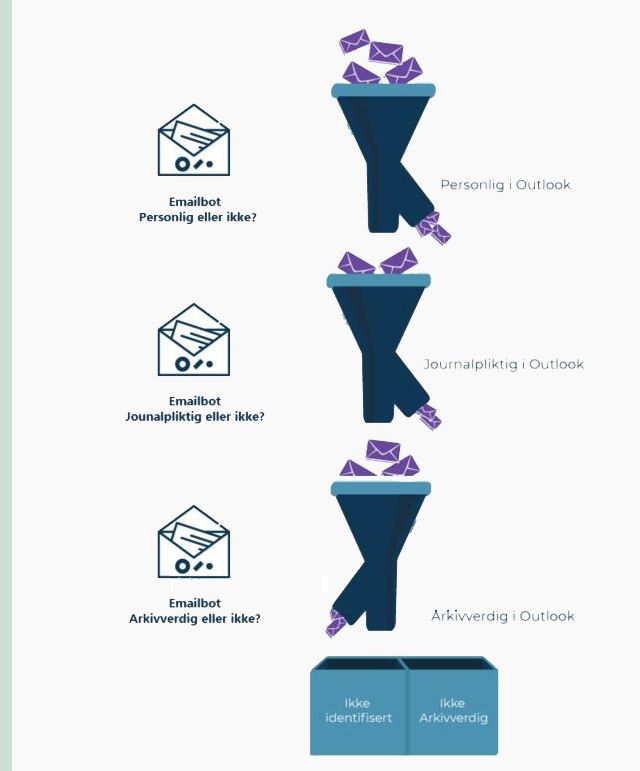
I denne fasen brukes DAM som beslutningsstøtteverktøy og skal benyttes som en veiledning for saksbehandlere i vurderingen av om e-poster er av personlig karakter, journalpliktig og arkivpliktig.
Behandling av personopplysninger i forbindelse med journalføringen og arkiveringen skjer i dag med hjemmel i personvernforordningen art. 6 nr. 1 bokstav c), «behandlingen er nødvendig for å oppfylle en rettslig forpliktelse som påhviler den behandlingsansvarlige.»
Den rettslige forpliktelsen til å ha arkiv finner vi i arkivloven § 6 og forskrift om offentlege arkiv §§ 9 og 10. For journalplikt finner vi i tillegg forpliktelsen i offentligetsloven § 10.
Sandkasseprosjektet foreslår at offentlige virksomheter bygger på artikkel 6 nr. 1 bokstav c også når de benytter digitale verktøy, som DAM, for å effektivisere og organisere arbeidet med arkiv.
Rettslig grunnlag for etterlæringsfasen
Det er et stort teknologisk framskritt, at en del kunstig intelligens-vertøy kan ha evnen til å lære. Når algoritmen lærer etter hvert som den blir brukt, kaller vi det etterlæring. Inferensen (altså resultatet av at algoritmen er benyttet på et nytt datagrunnlag) inngår i algoritmen, og slik blir verktøyet dynamisk justert for å bli mer treffsikkert.
Etterlæring kan være en utfordring for personvernjussen. Selv om det finnes rettslig grunnlag til å bruke kunstig intelligens til arkivering, for eksempel basert på behovet for å oppfylle en rettslig forpliktelse, er det ikke gitt at det finnes rettslig grunnlag for etterlæring av algoritmen.
I personvernforordningen artikkel 6 nr. 1 er det listet opp seks alternative vilkår som kan gi rettslig grunnlag for behandling av personopplysninger. De alternativene som det er mest aktuelt å vurdere i dette tilfellet, er vilkårene i bokstav c og bokstav e:
- Behandlingen er nødvendig for å oppfylle en rettslig forpliktelse (bokstav c).
- Behandlingen er nødvendig for å utføre en oppgave i allmenhetens interesse (bokstav e).
I begge tilfellene krever loven at det i tillegg finnes hjemmel for behandlingen i en annen lov jf. art. 6 nr. 3.
Dagens arkivlov sier ingenting om at e-post eller annet arkivverdig material kan brukes for å videreutvikle maskinlæringssystemer eller andre digitale verktøy. DAM hadde vært på tryggest grunn om arkivloven eksplisitt åpnet for at materialet behandlet i forbindelse med utførelse av arkiveringsplikten samtidig kan benyttes til forbedring eller videreutvikling av digitale verktøy. Det er likevel mulig at etterlæringen kan anses som et utslag av å bruke verktøyet, og på den måten har rettslig grunnlag i artikkel 6 nr. 1 bokstav c, på samme måte som for bruksfasen.
Det er et klart samfunnsmessig behov for å effektivisere og forbedre rettsikkerheten knyttet til arkivering. Hvordan tilgangen til arkivmateriale for videreutvikling av maskinlæring skal løses, er en oppgave for lovgiveren. Datatilsynet har sett eksempler på at enkelte virksomheter får hjemmel til å benytte innsamlede data til utvikling av it-systemer, se lov om statens pensjonskasse § 45 b.
En måte å løse denne utfordringen på, er å bygge algoritmen på en slik måte at inferensen uansett ikke vil inneholde personopplysninger. Da gjelder ikke personvernforordningens, og det er fritt frem for å trene algoritmen. En annen variant, dersom inferensen inneholder personopplysninger, er å anonymisere dataene før algoritmen etterlæres. Da er det ikke lenger personopplysninger, og modellen kan trenes uten krav om rettslig grunnlag.
Et alternativ kan også være om den enkelte bruker av DAM selv kan skru av eller på etterlæring av algoritmen, enten generelt eller med mulighet for å unnta den enkelte e-post fra inferensen. Dette vil dessuten være et positivt tiltak med tanke på åpenhet om hvordan verktøyet behandler personopplysninger, og det kan sikre at f.eks. privat e-post ikke inngår i treningen. En bivirkning av en slik løsning kan riktignok bli, at datagrunnlaget kan sementere en feilaktig arkiveringspraksis.
Er det lov å behandle særlige kategorier av personopplysninger?
I e-postkassa til en saksbehandler i NVE kan DAM finne informasjon fra den lokale fagforeninga, sammen med e-post til sjefen om sykdom. Noen bruker kanskje også virksomhetens e-post til privat kommunikasjon. Der kan DAM også finne informasjon både om saksbehandlerens religion og seksuelle orientering. Alle disse eksemplene regnes som særskilte kategorier, jf. personvernforordningen artikkel 9. Det er bare lov å behandle disse opplysningene dersom vilkårene i artikkel 9 nr. 2 er oppfylt.
Sandkassa antar at NVE kan bygge på vilkåret om «at behandlingen er nødvendig av hensyn til viktige allmenne interesser», i bokstav g for å bruke DAM. Det er illustrerende i forarbeidene til Nav-loven, der departementet legger til grunn at effektiv saksbehandling i Arbeids- og velferdsetaten og Statens pensjonskasse omfattes av «viktige allmenne interesser» i personvernforordningen artikkel 9 nr. 2 bokstav g.
En annen viktig del av vilkåret er at behandlingen skal «stå i et rimelig forhold» til målet som søkes oppnådd. I denne forholdsmessighetsvurderingen har sandkassa lagt vekt på at forslaget bare skal gå til saksbehandleren, og at inngrepet i personvernet derfor er begrenset. Vi anbefaler dessuten instrukser som forbyr eller begrenser bruk av virksomhetens e-post til private gjøremål for å begrense omfanget av privat e-post som blir behandlet i løsningen.
Forbudet mot overvåking i e-postforskriften
Så langt har vi forholdt oss til personvernforordningen. Men det er også relevant å vurdere DAM opp mot e-postforskriften med sitt forbud mot «å overvåke arbeidstakers bruk av elektronisk utstyr, herunder bruk av Internett» (§ 2, andre ledd).
Se e-postforskriften (på lovdata.no)
En arbeidsgiver vil altså ha lov til innføre DAM, så lenge bruken ikke innebærer overvåking av arbeidstakerne. Kan innføring av DAM sees på som overvåking av de ansattes bruk av elektronisk utstyr?
Hva som ligger i «å overvåke» er ikke nærmere definert i forskriften. I forarbeidene til tilsvarende regler i den gamle loven er det framhevet at tiltaket skal ha en viss varighet eller skje gjentatte ganger. Overvåking står i motsetning til enkeltstående innsyn, som er tillatt i flere situasjoner. I forarbeidene er det også understreket at det ikke bare er et spørsmål om formålet er å overvåke. Arbeidsgiveren skal også legge vekt på om de ansatte kan oppleve situasjonen som overvåkning.
Praksis fra Datatilsynet er ikke entydig, med tanke på om arbeidsgiver faktisk skal se personopplysningene for at det skal regnes som overvåking. Overvåkingsbegrepet favner vidt, og en naturlig språklig forståelse av begrepet kan tale for at også innsamling og systematisering rammes av forbudet. At bestemmelsen retter seg mot arbeidsgivers overvåking trekker i retning av at arbeidsgiveren i det minste må kunne ha adgang til opplysningene om arbeidstakerne for å rammes av forbudet. Dette var også sandkassas standpunkt i prosjektet med Secure Practice.
Se sluttrapporten fra Secure Practice-prosjektet
Etter diskusjonene i sandkasseprosjektet var det enighet om at DAM som beslutningsstøtte nok ikke vil omfattes av forbudet mot overvåking. Vi har lagt vekt på at løsningen bare lager et forslag i saksbehandlerens e-postkasse og at informasjonen om kategoriene ikke blir sendt videre.
I tillegg anbefaler sandkasseprosjektet tekniske og juridiske tiltak for at arbeidsgiveren ikke skal få tilgang til opplysningene som blir samlet inn om hver ansatt i løsningen. Et eksempel på tiltak er å innføre instrukser som forbyr eller begrenser bruk av virksomhetens e-post til private gjøremål, slik som nevnt under avsnittet om særskilte kategorier.