Ny teknologi kan medføre nye måter å behandle personopplysninger på, som ikke ble tatt høyde for da lovene, som regulerer NAVs behandling av personopplysninger, ble utformet. Utvikling og bruk av kunstig intelligens krever behandling av store mengder data – ofte personopplysninger – som sammenstilles og analyseres i en skala som ikke er mulig med andre hjelpemidler.
Det kreves tydelige lovhjemler for utvikling av kunstig intelligens i det offentlige. Disse hensynene blir forsøkt ivaretatt gjennom kravene til klare hjemler i personvernforordningens artikler 5, 6 og 9, Grunnloven § 102 og den europeiske menneskerettighetskonvensjonen artikkel 8, i tillegg til rettspraksis knyttet til disse bestemmelsene.
Generelt om rettslig grunnlag
Det rettslige grunnlaget som er mest aktuelt å vurdere for NAVs prediksjonsmodell, er artikkel 6-1 e. Den sier at personopplysninger kan behandles dersom det er nødvendig for å utøve offentlig myndighet, som den behandlingsansvarlige er pålagt. I tillegg kreves grunnlag etter artikkel 9 om man behandler særlige kategorier personopplysninger. Det gjør NAVs prediksjonsmodell, og dette gjelder spesielt helseopplysninger. NAV bruker derfor artikkel 9-2 b, som gir grunnlag for behandling av særlige kategorier personopplysninger for utøvelse av trygderettslige plikter og rettigheter.
Både artikkel 6-3 og artikkel 9-2 b krever et supplerende rettsgrunnlag i nasjonal rett. Det trenger ikke være en eksplisitt eller spesifikk hjemmel for den nøyaktige behandlingen. Formålet med behandlingen må følge av nasjonal rett eller være nødvendig for å utøve offentlig myndighet.
Se personvernforordningen artikkel 6.
Lovhjemmelen må likevel være klar nok til å sikre forutsigbarhet for de berørte, og hindre vilkårlighet i offentlig myndighetsutøvelse.
Se Grunnloven § 102 og EMK artikkel 8.
Dette krever at loven definerer hvordan opplysningene kan bli brukt, og setter grenser for hvordan myndighetene kan bruke opplysningene. Det må vurderes konkret om bestemmelsen er tilstrekkelig for den aktuelle behandlingen. Jo mer inngripende behandlingen er, jo tydeligere bør hjemmelen være.
NAVs supplerende rettsgrunnlag
NAV bygger på supplerende rettsgrunnlag i folketrygdloven § 8-7 a, sett i sammenheng med § 21-4 i samme lov og forvaltningsloven § 17. I tillegg har NAV en hjemmel til behandling av personopplysninger i lov om arbeids- og velferdsforvaltningen (NAV-loven) § 4 a første ledd.
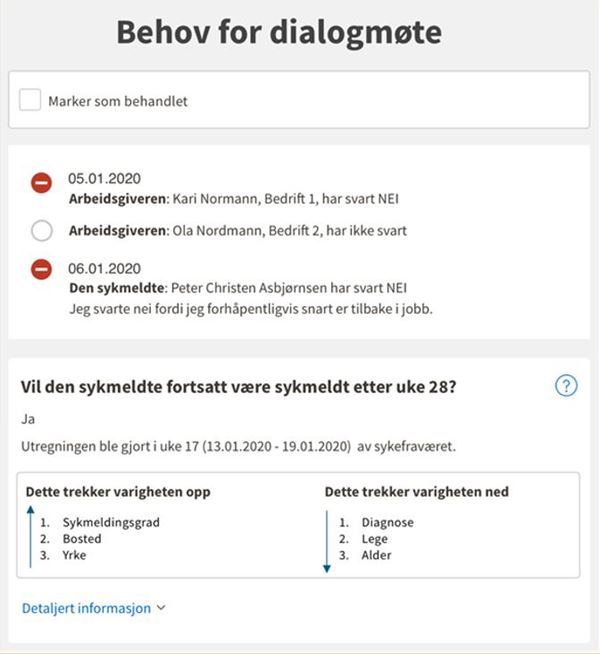
Folketrygdloven § 8-7 a regulerer noen av NAVs plikter til å følge opp sykmeldte. I § 8-7 a andre ledd er det regler om dialogmøte 2 som skal holdes i uke 26 av sykefraværet – unntatt «når et slikt møte antas å være åpenbart unødvendig».
Bestemmelsen må sees i sammenheng med den generelle bestemmelsen i lovens § 21-4. Den gir NAV en generell hjemmel til å samle inn opplysninger for å utøve sine oppgaver. Som forvaltningsorgan omfattes NAV også av den generelle bestemmelsen i forvaltningsloven § 17. Den krever at «forvaltningsorganet skal påse at saken er så godt opplyst som mulig før vedtak treffes».
Utviklingsfasen
Det er naturlig å dele spørsmålet om rettslig grunnlag i to, basert på de to hovedfasene i et KI-prosjekt; utviklingsfasen og anvendelsesfasen. De to fasene benytter personopplysninger på ulike måter.
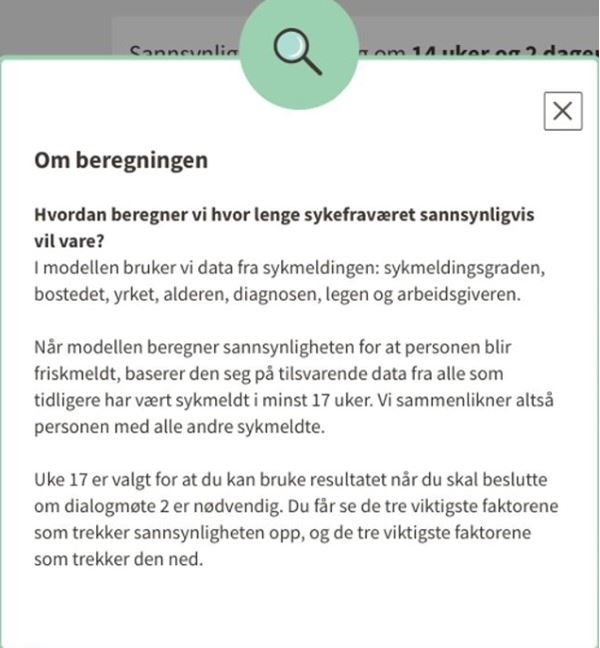
I utviklingsfasen bruker NAV en stor mengde historiske data – personopplysninger om tidligere sykmeldte – fra mange registrerte, for å trene opp en modell som skal predikere andre, fremtidige personers sykefraværslengde. I utviklingsfasen benyttes det ikke personopplysninger fra de som framtidig skal få oppfølging.
Spørsmålet blir dermed om de aktuelle bestemmelsene i loven (folketrygdloven § 8-7 a og § 21-4), som gir hjemmel til å behandle personopplysninger for å vurdere om det er åpenbart unødvendig å kalle inn til dialogmøte 2 i en konkret sak, også åpner for behandling av personopplysninger til utvikling av et KI-verktøy til bruk i saksbehandlingen?
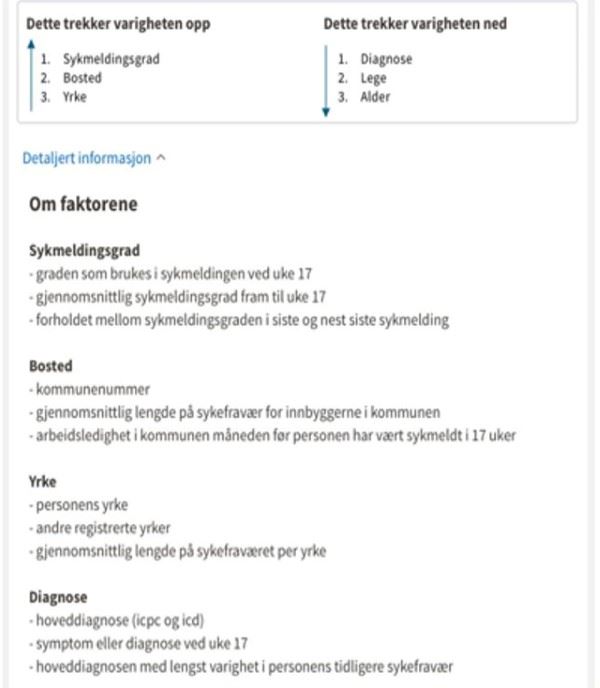
En naturlig forståelse av ordlyden tilsier at disse bestemmelsene ikke gir slik hjemmel. Sammenlignet med dagens vurderinger av dialogmøte 2, vil utvikling av prediksjonsmodellen behandle et langt større volum av personopplysninger som tilhører personer som ikke lenger er sykmeldte. Et viktig moment er også at disse opplysningene i stor grad vil være særlige kategorier personopplysninger, slik som diagnose, sykefraværshistorikk og informasjon fra fritekstfelt i sykmeldingen.
Den inngripende karakteren til behandlingen i utviklingsfasen taler også for at det må kreves en klar og tydelig hjemmel. Det er tvilsomt om folketrygdloven § 8-7 a, jf. § 21-4 og forvaltningsloven § 17 er spesifikke nok til å utgjøre et tydelig og klart supplerende rettsgrunnlag etter art. 6-1 e og artikkel 9-2 b. Det kommer ikke tilstrekkelig frem i lovene NAV bygger på som supplerende rettsgrunnlag at opplysningene til tidligere brukere skal kunne brukes til utvikling av kunstig intelligens.
Anvendelsesfasen
For anvendelsesfasen har NAV gjort en grundig vurdering av supplerende rettsgrunnlag for bruk av prediksjonsmodellen som beslutningsstøtte. Vurderingen bygger på supplerende rettsgrunnlag i folketrygdloven § 8-7 a, sett i sammenheng med § 21-4 og forvaltningsloven § 17. I tillegg har NAV en hjemmel til behandling av personopplysninger i NAV-loven § 4 a første ledd.
NAV har vurdert at det ikke kreves særlig hjemmel i lov for selve fremgangsmåten, herunder bruk av prediksjonsmodell, men at det må gjøres en vurdering av om fremgangsmåten er forholdsmessig, for å kunne angi om den sykmeldte skal kalles inn til dialogmøte 2 eller ikke.
Avgjørende for denne vurderingen er om bruken av prediksjonsmodellen kan anses som mer inngripende for brukeren. Videre er det også foretatt en vurdering av om den planlagte bruken av personopplysninger, både når det gjelder volum og hvordan opplysningene brukes, kan anses som nødvendig for å oppfylle kravet som loven stiller.
NAV har lagt til grunn at behandlingen av personopplysninger er både forholdsmessig og nødvendig for å oppnå formålet, og vil derfor kunne ha supplerende rettsgrunnlag for å bruke prediksjonsmodellen som beslutningsstøtte i selve anvendelsesfasen, forutsatt at de har et rettslig grunnlag for utviklingen.
Konklusjon om rettslig grunnlag
Etter vår vurdering kan NAV ha rettslig grunnlag for å behandle personopplysninger ved anvendelse av KI i denne sammenhengen. Det er imidlertid tvilsomt om det rettslige grunnlaget som NAV har oppgitt, kan utgjøre et rettslig grunnlag for å bruke personopplysninger til å utvikle en prediksjonsmodell, selv om modellen senere skal bidra til bedre oppfølging av sykmeldte. Rettslig grunnlag for utviklingen og den tilhørende behandlingen av personopplysninger er en forutsetning for at NAV skal kunne bruke prediksjonsmodellen som beslutningsstøtte i avgjørelser som gjelder om dialogmøte 2 skal holdes.
Det kan argumenteres for at det er samfunnsmessige fordeler med at NAV kan utvikle kunstig intelligens for å forbedre og effektivisere sitt arbeid. Samtidig er utvikling av kunstig intelligens en prosess som utfordrer flere viktige personvernprinsipper. For å sikre de registrertes rettigheter, vil tydelige og klare lov- eller forskriftshjemler for en slik utvikling være nødvendig. En lovprosess, med tilhørende høringsrunde og utredninger, vil bidra til å sikre en demokratisk forankring for utvikling og bruk av kunstig intelligens i offentlig forvaltning.
Konklusjonen over er basert på diskusjonene Datatilsynet og NAV har hatt i sandkasseprosjektet, og er derfor veiledende og ikke en avgjørelse fra Datatilsynets side. Ansvaret for å vurdere det rettslige grunnlaget for de aktuelle behandlingene, ligger hos NAV som behandlingsansvarlig.
Automatiserte beslutningsprosesser
Selv om en behandling er lovlig, gir personvernforordningen den registrerte rett til å ikke være gjenstand for automatiserte, individuelle avgjørelser, altså avgjørelser tatt uten menneskelig inngripen, dersom behandlingen har rettsvirkning for eller på tilsvarende måte i betydelig grad påvirker den enkelte. Den menneskelige involveringen må være reell, og ikke være fingert eller illusorisk.
Se personvernforordningen artikkel 22-1 og s. 20-21 i Art. 29 WPs retningslinjer om automatiserte, individuelle beslutninger.
Dersom prediksjonsmodellen kun brukes som en beslutningsstøtte, vil prediksjonen om sykefraværslengden inngå som ett av flere momenter i NAV-veiledernes vurdering av om den sykmeldte skal innkalles til dialogmøte. Den menneskelige vurderingen fører i slike tilfeller til at behandlingen ikke defineres som helautomatisert. Det kan likevel tenkes at beslutningen i praksis blir helautomatisert. Veiledernes arbeidsbelastning og kunnskap om algoritmen, samt prediksjonenes opplevde og faktiske treffsikkerhet, vil påvirke risikoen for at mennesket i loopen – veilederen – på autopilot aksepterer ethvert resultat fra prediksjonsmodellen.
Flere tiltak kan redusere denne risikoen. Gode rutiner og opplæring av veilederne vil være sentralt. Informasjonen som de får i forbindelse med bruk av verktøyet, må være forståelig og sette dem i stand til å vurdere prediksjonen opp mot andre momenter. Det må også innføres rutiner for å avdekke om avgjørelsene blir helautomatisert.
NAV ønsker riktignok på sikt å helautomatisere prosessen rundt innkalling til dialogmøte 2. Det finnes unntak fra forbudet mot helautomatiserte avgjørelser, men det forutsetter at avgjørelsen ikke har «rettsvirkning for eller på tilsvarende måte i betydelig grad påvirker vedkommende». Så har modellen det?
Se personvernforordningen artikkel 22-1 og 22-4.
NAVs prediksjonsmodell, som skal anslå lengden på sykefravær, innebærer profilering og er en automatisert behandling. Så lenge modellen reelt blir brukt som beslutningsstøtte, er ikke selve avgjørelsen automatisert. Det er avgjørelsen om å kalle inn til dialogmøte eller ikke, som har potensial til å ha rettsvirkning eller tilsvarende påvirkning på den registrerte, ikke prediksjonen isolert.
Spørsmålet blir da om innkallingen til dialogmøte 2 har rettsvirkning, eller på tilsvarende måte påvirker brukeren. En avgjørelse har «rettsvirkning» dersom den påvirker personens juridiske rettigheter, slik som retten til å stemme eller kontraktsrettslige virkninger. En innkalling til dialogmøte omfattes ikke av dette. Da gjenstår det å vurdere om avgjørelsen som gjelder dialogmøte påvirker brukeren på en betydelig måte, tilsvarende som en rettsvirkning.
Svaret blir ja dersom avgjørelsen har potensial til å påvirke den enkeltes omstendigheter, adferd eller valg, har en langvarig eller permanent påvirkning, eller fører til ekskludering eller diskriminering. Avgjørelser som påvirker noens økonomiske omstendigheter, slik som tilgang til helsetjenester, vil kunne kalles en påvirkning tilsvarende en rettsvirkning.
Se s. 21-22 i Art. 29 WPs retningslinjer om automatiserte, individuelle beslutninger.
Avgjørelse om dialogmøte 2 er ikke et enkeltvedtak, men det vil kunne argumenteres for at det i «betydelig grad påvirker», og i en helautomatisert utgave vil kunne falle inn under art. 22. I tilknytning til offentlig virksomhet vil det ikke bare være enkeltvedtak som faller inn under art. 22, noe som har støtte i forarbeidene til ny forvaltningslov. Hva som faller inn under «rettsvirkning» eller «betydelig grad påvirker», må vurderes konkret ut fra hvilke konsekvenser avgjørelsen har for den registrerte. For NAVs prediksjonsmodell kan det tenkes et skille mellom situasjoner der det innkalles til dialogmøte 2, og der det ikke innkalles til møte.
Dersom den sykmeldte ikke blir kalt inn til dialogmøte, oppstår det ingen plikt for vedkommende. Samtidig beholder den sykmeldte retten til å kreve et dialogmøte. I slike situasjoner vil avgjørelsen ha mindre inngripende virkning på den registrerte, så lenge muligheten til å be om dialogmøte er reell. Samtidig skal dialogmøte 2 hjelpe den sykmeldte i å komme tilbake i jobb. Ikke alle sykmeldte vil ha ressurser til å benytte seg av retten til å be om dialogmøte. Dette kan kanskje delvis ivaretas med god informasjon til de registrerte.
I de situasjonene en sykmeldt blir innkalt til dialogmøte 2 – som er hovedregelen etter folketrygdloven § 8-7 a – vil det oppstå en plikt for den sykmeldte til å møte opp. Manglende etterlevelse av denne plikten, vil i ytterste konsekvens kunne føre til bortfall av sykepenger. I slike tilfeller vil plikten til å møte på dialogmøte 2 kunne ha stor påvirkning på den sykmeldte, og vil kunne falle inn under vilkåret i artikkel 22.
Kort oppsummert kan avgjørelser om å kalle inn til dialogmøte kunne nå opp til terskelen i artikkel 22, noe som utløser et forbud. Avgjørelser om ikke å kalle inn vil kunne falle utenfor terskelen, forutsatt at den sykmeldtes rett til å be om dialogmøte er reell. Om det er praktisk mulig å skille avgjørelsene på denne måten, vil være opp til NAV å vurdere.