Hvordan forklare bruken av kunstig intelligens?
Åpenhet er et grunnleggende prinsipp i personvernforordningen. I tillegg til å være en forutsetning for å avdekke feil, forskjellsbehandling eller andre problematiske forhold, bidrar det til å skape tillit og setter enkeltindividet i stand til å bruke sine rettigheter og ivareta sine interesser.

Se personvernforordningen artikkel 5-1 a og fortalepunkt 58.
Åpenhet og forklarbarhet
I tilknytning til KI bruker man ofte begrepet forklarbarhet, som går direkte på de KI-spesifikke problemstillingene knyttet til åpenhet, og som kan sies å være en konkretisering av åpenhetsprinsippet. Tradisjonelt har åpenhet dreid seg om å vise hvordan ulike personopplysninger brukes, men bruk av KI krever andre metoder, som kan forklare komplekse modeller på en forståelig måte.
Forklarbarhet er et interessant tema, både fordi det kan være en utfordring å forklare komplekse systemer og fordi hvordan kravet til åpenhet skal implementeres i praksis vil variere fra løsning til løsning. I tillegg muliggjør maskinlæringsmodeller forklaringer som ser radikalt annerledes ut enn de vi er vant til, gjerne basert på avanserte matematiske og statistiske modeller. Dette åpner for en viktig avveiing mellom en mer korrekt, teknisk forklaring eller en mindre korrekt, men mer forståelig forklaring.
I denne delen av rapporten deler vi vurderinger og konklusjoner fra diskusjonene vi hadde rundt åpenhet og forklarbarhet i NAVs løsning for å predikere sykefraværslengde. Veiledere på NAV-kontor og den sykmeldte som individ er de to mest sentrale målgruppene for forklaring i dette tilfellet.
Krav til åpenhet
Uavhengig om du bruker kunstig intelligens eller ikke er det visse krav til åpenhet dersom du behandler personopplysninger. Kort oppsummert er disse:
- De registrerte må få informasjon om hvordan opplysningene brukes, enten opplysningene hentes inn fra den registrerte selv eller fra andre. (Se personvernforordningen artikkel 13 og 14.)
- Informasjonen må være lett tilgjengelig, for eksempel på en hjemmeside, og være skrevet i et klart og forståelig språk. (Se personvernforordningen artikkel 12.)
- Den registrerte har rett til å få vite om det behandles opplysninger om henne og eventuelt innsyn i egne opplysninger. (Se personvernforordningen artikkel 15.)
- Det er et grunnleggende krav at all behandling av personopplysninger skal gjøres på en åpen måte. Det betyr at det er krav om å vurdere hvilke åpenhetstiltak som må til for at den registrerte skal kunne ivareta egne rettigheter. (Se personvernforordningen artikkel 5.)
I det første kulepunktet er det krav om å gi informasjon om hvordan opplysningene brukes. Det inkluderer blant annet kontaktinformasjon til den behandlingsansvarlige (i dette tilfellet NAV), formålet med behandlingen og hvilke kategorier personopplysninger som blir behandlet. Dette er informasjon som typisk formidles i personvernerklæringen.
Les gjerne mer i detalj om krav om åpenhet i KI-løsninger i rapporten Kunstig intelligens og personvern (2018)
Når det gjelder kunstig intelligens kan det være verdt å merke seg kravet om å forklare algoritmens underliggende logikk. Det er et spesifikt krav å gi «relevant informasjon om den underliggende logikken samt om betydningen og de forventede konsekvensene av en slik behandling for den registrerte». Det er ikke nødvendigvis innlysende hvordan disse kravene skal forstås. Man bør etterstrebe at informasjonen som gis er meningsfull, fremfor å bruke kompliserte forklaringsmodeller basert på avansert matematikk og statistikk. Det understrekes også i forordningens fortale (punkt 58) at teknologisk kompleksitet gjør åpenhet ekstra viktig. De forventede konsekvensene bør også eksemplifiseres, for eksempel ved hjelp av visualisering av tidligere utfall.
Det spesifiseres at dette i hvert fall skal gjøres i tilfeller der det skjer automatiserte avgjørelser eller profilering etter artikkel 22. Om det må informeres om logikken dersom det ikke er automatiserte avgjørelser eller profilering, må vurderes fra sak til sak basert på om det er nødvendig for å sikre en rettferdig og åpen behandling.
Automatisk eller ikke?
Hvis en behandling kan kategoriseres som en automatisert avgjørelse eller profilering etter artikkel 22, stilles det ekstra krav til åpenhet. Du har blant annet rett til å vite om du blir utsatt for automatiserte avgjørelser, herunder profilering. Det er også et krav at individet får relevant informasjon om den underliggende logikken, betydningen av og de forventede konsekvensene av en slik behandling, som nevnt over.
Relevant regelverk
Det forsterkede kravet til åpenhet ved automatiserte avgjørelser eller profilering etter artikkel 22, omtales i:
Men har du rett på en individuell forklaring om hvordan algoritmen kom frem til avgjørelsen? Selve lovteksten sier ikke det, men i fortalen står det i punkt 71 at den registrerte har krav på en forklaring på hvordan modellen kom frem til resultatet, det vil si hvordan opplysningene er vektet og vurdert i de konkrete tilfellene, dersom man faller inn under artikkel 22. I punkt 60 står det også at den registrerte bør «informeres om forekomsten av profilering og konsekvensene av dette.» Fortalen i seg selv er ikke juridisk bindende og gir ikke alene en rett til en individuell forklaring.
Åpenhetskravet betyr nødvendigvis ikke at kildekoden må gjøres tilgjengelig, men forklaringen må gjøre den registrerte i stand til å forstå hvorfor en avgjørelse ble som den ble. Dette gjelder der avgjørelsen faller inn under artikkel 22 om automatiserte individuelle avgjørelser. Det kan også tenkes tilfeller der rettferdighets- og åpenhetsprinsippet stiller høyere krav til forklaring, for eksempel ved profilering som ikke oppfyller vilkårene i artikkel 22, men hvor gode grunner tilsier at den registrerte burde få slik informasjon.
En meningsfull forklaring er ikke bare avhengig av tekniske og juridiske krav, men også språklige og designmessige vurderinger. Det må også vurderes hvilken målgruppe forklaringen retter seg mot, noe som vil kunne innebære en forskjell for veiledere og brukere. Også selve den praktiske anvendelsen av forklaringsmodellen i veiledernes arbeidshverdag vil kunne innebære at tilliten og opplevelsen av om en får en meningsfull forklaring vil kunne variere, ved at forklaringene som gis fremstår som standardiserte og derfor gir liten veiledning over tid. Samfunnsmessige forhold som tillit til virksomheten, vedtakets betydning og tilliten til KI-systemer generelt vil også kunne påvirke opplevelsen av en meningsfull forklaring.
Et sentralt spørsmål for NAV har vært om prediksjonsmodellen for sykefraværslengde er en automatisert avgjørelse og utløser disse ekstra kravene eller ikke. I dette tilfellet er det liten tvil om at prediksjonsmodellen ikke er en helautomatisert behandling. Prediksjonen vil være ett av flere informasjonselementer en veileder skal vurdere før avgjørelsen tas.
Likevel finnes det grunner til å informere om logikken og virkemåten i modeller som ikke er helautomatiserte. Prediksjonsmodellen gjennomfører uansett profilering, og en meningsfull forklaring bidrar til å bygge tillit og er et uttrykk for ansvarlighet. I tillegg vil en meningsfull forklaring sette veilederen bedre i stand til å vurdere hvor mye vekt hen skal gi anbefalingen algoritmen gir.
Forordningens definisjon av profilering
«enhver form for automatisert behandling av personopplysninger som innebærer å bruke personopplysninger for å vurdere visse personlige aspekter knyttet til en fysisk person, særlig for å analysere eller forutsi aspekter som gjelder nevnte fysiske persons arbeidsprestasjoner, økonomiske situasjon, helse, personlige preferanser, interesser, pålitelighet, atferd, plassering eller bevegelser»
(personvernforordningen artikkel 4)
Uavhengig av om det er snakk om en helautomatisert beslutning eller ikke plikter databehandleren å gi nok informasjon til at brukeren har den informasjonen som er nødvendig for å kunne ivareta sine rettigheter. NAVs sentrale rolle i offentlig forvaltning gir opphav til en asymmetrisk maktrelasjon mellom bruker og etat, som også er et argument for å etterstrebe en så meningsfull forklaring som mulig, til tross for at modellen ikke er helautomatisert.
Stoler vi på algoritmen?
Gode forklaringer av algoritmen og dens prediksjoner øker tilliten hos de som skal bruke systemet, noe som er helt sentralt for å oppnå den ønskede verdien. De flere tusen NAV-ansatte som jobber med brukerveiledning spiller derfor en avgjørende rolle.
Systemet som predikerer sykefraværslengde er et beslutningsstøttesystem, men hva skjer hvis systemet i praktisk anvendelse blir et beslutningssystem? En veileder i NAV gjennomgår mange saker i løpet av en vanlig arbeidsdag. Hvis det virker som om algoritmen gir konsekvente gode anbefalinger kan det jo være fristende å alltid følge den. Veilederen tenker kanskje at algoritmen sitter på så mye data at den vet best, og at det skal litt til for å ikke følge anbefalingen? Hvor lett er det for en nyansatt å ikke følge anbefalingen til algoritmen?
Eller hva hvis veilederne syns at algoritmen gir merkelige anbefalinger og ikke stoler på dem? En konsekvens av det ville være at veilederne konsekvent ikke bruker det som beslutningsstøtte. Det ville også ha vært uheldig fordi hele hensikten med løsningen er å hjelpe veilederne til å ta gode valg, slik at innkallingene oftere treffer riktig. Ideelt sett vil en slik modell redusere de tilfeldige variasjonene blant veilederne og føre til mer enhetlig praksis, i tillegg til å redusere kostnader.
I sandkassen diskuterte vi risikoene for at veileder lener seg for mye eller for lite på beslutningsstøttesystemet, og hvordan legge til rette for at systemet oppleves som en reell støtte for veileder og blir brukt på en god og riktig måte. At veileder får god opplæring og instrukser i hvordan algoritmen fungerer og skal brukes, samt en meningsfull forklaring i enkelttilfeller, er viktig for å redusere risikoen for en «snikautomatisering» eller at den ikke tas med i vurderingen i det hele tatt. Når NAV-veilederne forstår modellens oppbygning, virkemåte og oppførsel, vil det være enklere å vurdere prediksjonen på et selvstendig og trygt grunnlag. I tillegg kan forklaringen bidra til å hjelpe veileder å avdekke diskriminering, uønsket forskjellsbehandling og feil. Her vil en forklaring knyttet til en enkelt avgjørelse være supplert med informasjon knyttet til utfallet for enkelte grupper det er naturlig å sammenlikne med.
Forklaring av modellen
Her er et eksempel på hvordan en generell forklaring om hvordan modellen opererer, kan se ut for veilederen som bruker systemet.
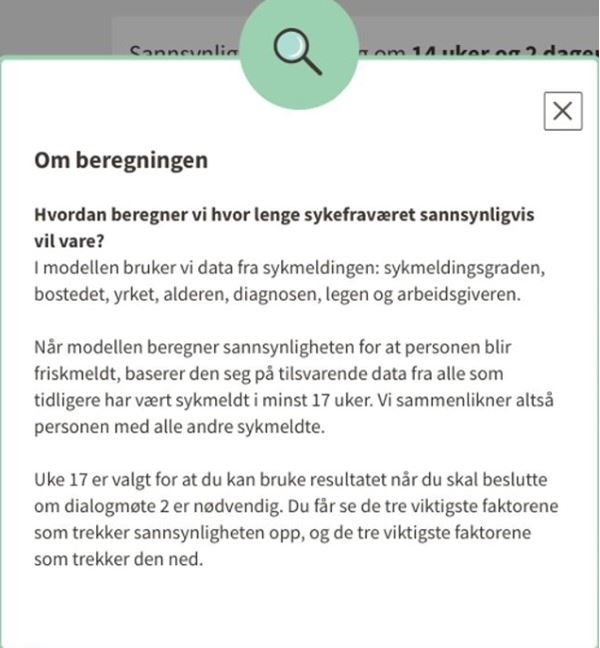
Hvordan ser en meningsfull forklaring ut?
Et spørsmål vi har diskutert i sandkassen er hvordan en meningsfull forklaring ser ut i praksis i NAVs tilfelle. Målgruppene for åpenhet i løsningen er de sykmeldte og NAV-veiledere. Forklaringene er både globale, altså på systemnivå, og lokale utfallsforklaringer. De to ulike nivåene vil følgelig ha delvis ulike målgrupper, og det vil stilles ulike krav til hvordan de innrettes.
NAV ønsker å informere i forkant av behandlingen om at brukeren har rett til å protestere mot at det i det hele tatt skal gjøres en prediksjon basert på en profilering. De ønsker også å informere om hvordan modellen er bygget og hvilke variabler som inngår. NAV vurderer også å informere den individuelle brukeren om de viktigste faktorene som trekker den predikerte sykefraværsvarigheten opp og de viktigste faktorene som trekker den ned.
En meningsfull forklaring er ikke bare avhengig av tekniske og juridiske krav, men også språklige og designmessige vurderinger. Forklaringen må tilpasses til målgruppen den retter seg mot. For eksempel trenger veiledere i NAV forklaringer som kan anvendes i praksis i en hektisk hverdag. NAV må derfor balansere og avveie mellom dybde og forenklinger som gjør det mulig å ta forklaringen i bruk. Forklaringen må dessuten integreres med øvrig informasjon veileder har tilgang til. Et konkret eksempel er at NAV ikke kan presentere informasjon om hvordan 100 variabler har bidratt til en prediksjon. NAV må gruppere disse sammen og gjøre et utvalg. Det kreves i tillegg ekstra årvåkenhet dersom forklaringen retter seg mot barn eller sårbare grupper. NAVs modell vil kunne inkludere flere særskilte kategorier personopplysninger om sårbare grupper og NAV vil derfor måtte vurdere å tilpasse språk, innhold og form basert på det.
Informasjon om data
Slik ser NAV for seg at man kan bli presentert hvilke data som brukes og legges til grunn på hvilken måte i modellen.
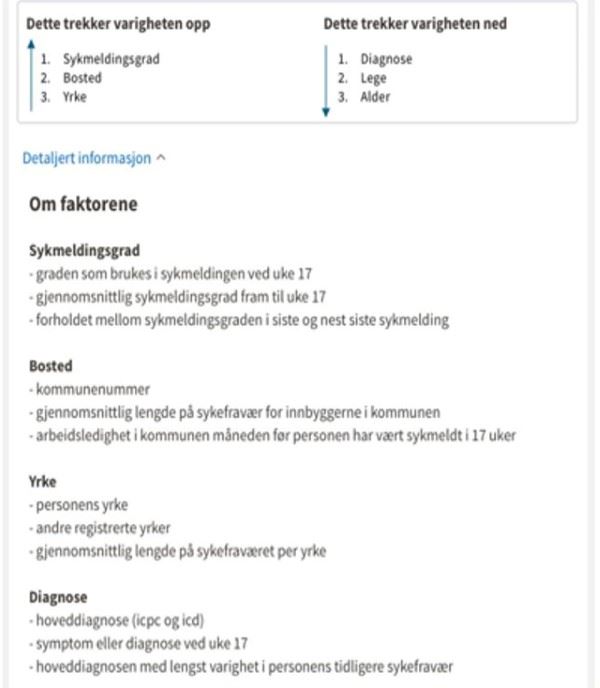
Når det gjelder veiledere planlegger NAV å forklare hvordan modellen virker generelt og beskrive hvordan de skal bruke resultatet fra modellen i saksbehandlingsrutiner. I tillegg skal veiledere få forklaringer på enkeltsaksnivå og informasjonselementer modellen har lært fra som en del av informasjonsgrunnlaget for å ta den endelige avgjørelsen om brukeren kalles inn til dialogmøtet eller ikke. Prediksjonen skal inngå som ett av flere momenter som er tilgjengelig for veilederen, inkludert den informasjonen en veileder baserer en avgjørelse på i dag.
I tillegg til de to hovedmålgruppene (brukere og veiledere) som nevnes her har NAV identifisert forretningssiden/ledelse, de ansvarlige for modellen og tilsynsmyndigheter som andre målgrupper som vil ha behov for og krav på en forklaring på hvordan algoritmen fungerer.
NAV ønsker å ta sin del av ansvaret når det kommer til åpenhet rundt bruken av algoritmer. Et mulig tiltak som diskuteres er å informere om hvordan NAV i stort ønsker å ta i bruk kunstig intelligens. NAV søker også å bidra til bred informasjon og opplyst debatt om bruken av kunstig intelligens gjennom mediebildet. Et siste tiltak er å informere og involvere brukerutvalg i forkant av og underveis i utviklingen av tjenester som baserer seg på kunstig intelligens.