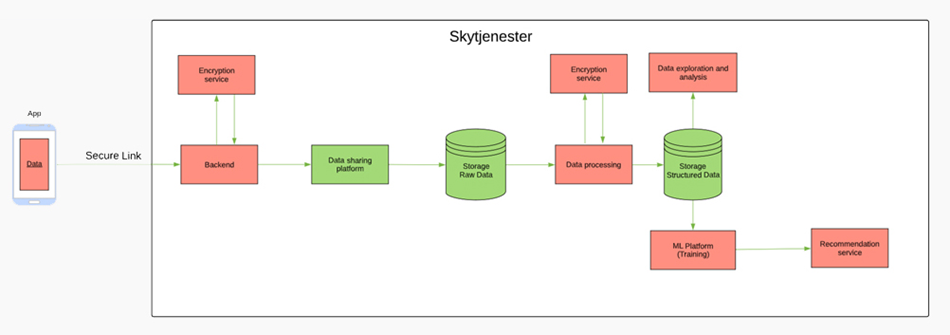
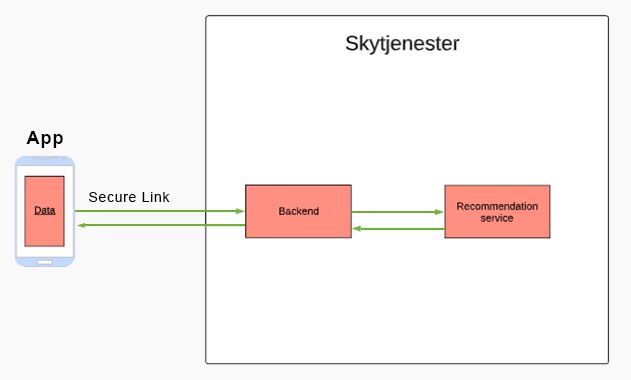
The customer's identity is replaced here with a pseudonymised number. The transfer of the personal data from the user's device to Ruter first takes place when Ruter has reached the stage in the development phase when the AI model is to be trained using personal data. It is uncertain as to how long it will take between the collection and storage of data on the user's local device and until the user is given the choice to share the information with Ruter.
Article 13 of the GDPR requires that information be provided to the data subject no later than at the point in time when the personal data is collected. This is solved by Ruter providing information to the data subject before such data collection commences. There may be nuanced differences in what information Ruter needs to provide at the time of local collection and central collection. We will return to this and to specific issues relating to informed consent.
Article 13 contains a long list of information that must be provided to the data subject. Here we will focus on Delivery 1.2, and the data subjects’ right to information in connection with the development of artificial intelligence. Of greatest importance are the more complex parts of the obligation to provide information, i.e. how Ruter processes personal data in connection with the development of the AI model and for what purposes.
Obligation to provide information, AI and profiling
General information to the data subjects during the development phase
Ruter's project is in the preparation phase, and an important question is: How can Ruter provide the customers with the information they are entitled to when the solution has not been fully developed?
As mentioned in the introduction, the purpose of collecting and storing personal data locally is that personal data can later be sent to Ruter centrally for the development of AI. Ruter must therefore:
- Provide information during the preparation phase that the personal data will be stored until the AI model is ready.
- Provide new information during the development phase when the personal data is sent to Ruter centrally and the training of the AI model will commence.
During the preparation phase, it is easy to understand how Ruter will collect personal data and store this locally on the user's device. This phase will not involve AI. It is therefore a simple task to provide the data subject with information about this. The challenge is to comply with the requirement for providing information about the planned development of the AI model centrally at Ruter.
We have come to the conclusion that the list relating to the planned processing of personal data in "About Ruter's project" above is a good starting point.
The obligation to provide information has to be understood in light of the specific risk for the data subjects
We have discussed the considerations behind the transparency principle and how these influence the information that Ruter is obligated to provide to the users. Among the considerations behind the transparency principle is that data subjects must be able to safeguard their rights under the GDPR. Another important consideration is that information has an important control function vis-à-vis the controller, in that they have an obligation to explain to those concerned how their personal data is being processed.
The information that is necessary in order to safeguard these considerations will depend on how invasive the processing is in terms of the rights and freedoms of the data subjects. AI models that control what government benefits one is entitled to, or whether one should have access to government services, are examples of invasive processing of personal data. More detailed information will then need to be provided to the data subjects than for processing activities that have fewer consequences for the data subjects.
In the sandbox project, we have discussed that Ruter's model has few consequences for the data subjects, and that Ruter's use of AI does not pose any particular risk to the rights and freedoms of the data subjects. At the same time, Ruter is a publicly owned company and the sole provider of the public transport services in its area. We have therefore also discussed that Ruter is reliant on providing good information and a good user experience to ensure trust and that people will want to use their services. This particularly applies when the company intends to adopt new technology.
Special categories of personal data
One issue we have discussed in the sandbox project is whether favourite searches or travel patterns to and from the same address over time can infer that there are special categories of personal data. For example, one can envisage that a customer will regularly travel to and from a religious community, health institution or a political organisation and that this may reveal one’s religious faith, medical information or political affiliation.
Ruter has been clear that they do not intend to process special categories of personal data about the customers. We nevertheless agree that Ruter may process this type of data when they collect location data and travel searches over time.
In areas with a large number of stops, such as Jernbanetorget in Oslo, a more accurate GPS position is required to provide correct and relevant travel suggestions than in areas with few stops. As a data minimisation measure, Ruter will reduce the accuracy in areas with fewer stops. This may, for example, be appropriate outside the town/city centre, where there is a longer distance between stops and where the frequency of detached houses makes it easier to identify the user based on location. If, on the other hand, the user is at Jernbanetorget, there will be a need for complete accuracy to determine which stops are closest. In areas where the GPS location is relatively accurate, there is a greater risk that the data collected will reveal journeys to and from, for example, a religious community or a political organisation. The same applies in instances in which customers themselves search for specific addresses.
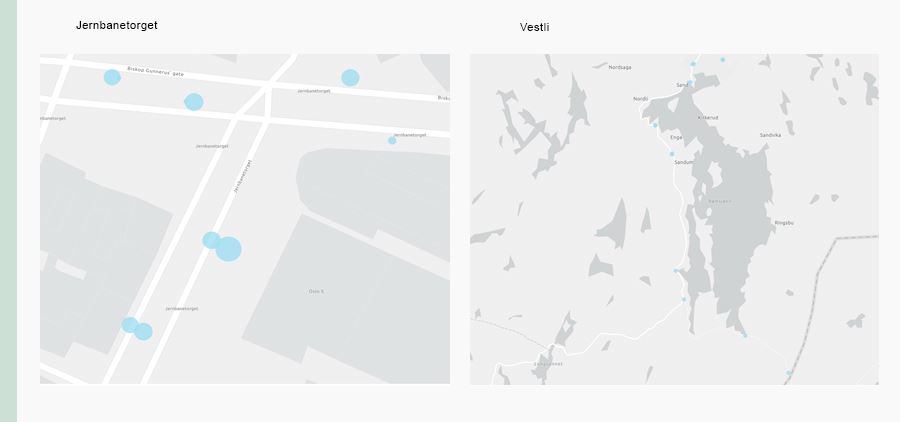
In the pictures above, the stops are marked to show distance and the various requirements for exact position.
Since there is a risk that Ruter will process special categories of data about customers, the customers must be informed of this to ensure they are aware of the risk.
Does Ruter’s service involve “profiling”?
An important question for Ruter has therefore been whether personalised travel suggestions will constitute profiling pursuant to the GDPR and whether this triggers an additional obligation to provide information to data subjects.
The definition of profiling in the GDPR
“any form of automated processing of personal data consisting of the use of personal data to evaluate certain personal aspects relating to a natural person, in particular to analyse or predict aspects concerning that natural person's performance at work, economic situation, health, personal preferences, interests, reliability, behaviour, location or movements”.
(Article 4 of the GDPR)
In Ruter's service, the company will use personal data to predict travel patterns and provide personalised travel suggestions. Our assessment is that this involves automated processing that uses personal data to analyse and predict a natural person's behaviour, location and movement. Ruter's use of AI therefore constitutes profiling pursuant to Article 4 (4) of the GDPR.
In the sandbox project, we have discussed whether profiling takes place in the development phase, because the user does not receive any travel suggestions during this phase. We have arrived at the joint conclusion that Ruter will test and validate the model using personal data during the development phase. This means that profiling will therefore also take place during the development phase.
Information about profiling that is not covered by Article 22
“The data subject shall have the right not to be subject to a decision based solely on automated processing, including profiling, which produces legal effects concerning him or her or similarly affects him or her.”
(Article 22 (1) of the GDPR)
In the sandbox project, we have concluded that Ruter's personalised travel suggestions will not have such an effect for the data subjects. Ruter's profiling is therefore not covered by Article 22.
The next question is what information Ruter is still obligated to provide regarding the profiling. Profiling is the processing of personal data, and needs to satisfy the general requirements for information in Articles 12 and 13 of the GDPR. In addition, we have discussed whether, when read in light of the recital, it can be inferred from the transparency principle that Ruter has an obligation to provide information about how the AI model functions.
Pursuant to Article 5(1)(a) of the GDPR, the controller must ensure that personal data is processed in a fair and transparent manner.
“The principles of fair and transparent processing require that the data subject be informed of the existence of the processing operation and its purposes. The controller should provide the data subject with any further information necessary to ensure fair and transparent processing taking into account the specific circumstances and context in which the personal data are processed. Furthermore, the data subject should be informed of the existence of profiling and the consequences of such profiling.”
(Recital 60, Our emphasis)
Pursuant to the Article 29 Working Party’s guidelines for transparency (paragraph 41), a fundamental consideration is that data subjects are able to understand in advance the scope and consequences of the processing of their personal data.
The Article 29 Working Party has also issued a statement regarding information that must be provided for profiling that falls outside of Article 22:
“It should be noted that, aside from the specific transparency requirements applicable to automated decision-making under Articles 13.2(f) and 14.2(g), the comments in these guidelines relating to the importance of informing data subjects as to the consequences of processing of their personal data, and the general principle that data subjects should not be taken by surprise by the processing of their personal data, equally apply to profiling generally (not just profiling which is captured by Article 22, as a type of processing.”
(Paragraph 41)
A legal duty to explain the underlying logic behind the profiling discussed in this sandbox project can hardly be inferred from an expanded interpretation of Articles 13 and 14 of the GDPR. However, the principles of transparency and fairness in Article 5 (1) (a) still dictate that Ruter must provide information about the underlying logic, to the extent that is necessary for the data subjects to be able to understand how Ruter processes their personal data, and thus enabling them to exercise their rights. This is also in line with the opinions of the Article 29 Working Party that the processing must be predictable for the data subject.
In the sandbox project, we have concluded that Ruter needs to provide the data subjects with general information about the fact that they are being profiled, and relevant information about how the underlying profiling logic functions. Ruter is also focussed on providing good information about this to ensure satisfaction and trust among customers. The requirement for transparency does not necessarily mean that the source code has to be made available; however, the explanation must enable the data subject to understand why a particular decision was made.
Explanation of the underlying logic
The term "underlying logic" is used in the GDPR. This means a general explanation of how a result is arrived at. The term does not include an explanation of how the specific result that applies to you was arrived at.
When explaining the underlying logic, Ruter should strive to ensure that the information provided is meaningful, rather than using complicated explanatory models based on advanced mathematics and statistics. It is also emphasised in recital 58 of the GDPR that technological complexity makes transparency extra important.
The most important factor is that the data subjects understand how Ruter's service determines travel suggestions, how they are profiled and the consequences of this. As mentioned in the introduction, Ruter's planned service is not particularly invasive for the data subjects. This also influences how detailed the information Ruter has to provide to the data subject needs to be in order for them to be able to safeguard their rights and ensure transparency and predictability.
Ruter's challenge in the preparation phase, when the company will start collecting personal data, and then later in the development phase, is that it is not entirely clear what underlying logic will be used. It will depend on which models end up functioning the best. However, what is clear is that these AI models are still going to use location and travel searches with the associated points in time. Ruter must inform the data subjects that the profiling is based on these categories of personal data.
See examples of what should be included in an explanation on page 31 of the Article 29 Working Party’s guidelines for automated, individual decisions and profiling. (external page)
Information relating to the transfer of data to third countries
Ruter is looking at two alternative solutions, one of which involves the transfer of data to third countries. The choice of solution will be based on Ruter's assessment of the transfer of personal data to third countries. The sandbox project did not address this. Even if the data flow should not involve a transfer, we agree that Ruter must provide information about the data flow to the data subjects and the assessments the company has made regarding transfers to third countries.
Since Ruter is using a cloud provider in this project, this could be considered a recipient of personal data pursuant to Article 4(9) of the GDPR. Ruter is obligated to provide information about recipients of personal data pursuant to Article 13(1)(e).
Information pertaining to where and how the personal data is processed is a prerequisite for the data subjects being able to exercise their rights. This is important information that the data subjects need to have in order to assess whether they wish to consent to the use of personal data.
We have discussed how it is challenging to provide information about the data flow and the assessments relating to transfers to third countries. Ruter needs to work more on this, however we agree that the simplified explanation and illustrations at the beginning of the report are a good starting point. We have also talked about how it is important that this information is presented to customers in layers to avoid the quantity of information overwhelming the reader. It is important to remember that the information must be easy for the customer to understand.
If Ruter concludes that personal data will be transferred out of the EEA, they are obligated to provide information about this and explain how Ruter does this in a lawful manner in accordance with Chapter V of the GDPR, cf. Article 13 (1)(f). The data subjects also need to be informed about where any necessary guarantees have been made available. Even if Ruter should come to the conclusion that they do not transfer personal data out of the EEA, the transparency principle dictates that Ruter should provide information about why this is their conclusion, and that they therefore do not need to satisfy the requirements in Chapter V of the GDPR relating to such transfers.
The information can, for example, be presented in layers under an overarching heading "We do not transfer your personal data out of the EEA - read more about this here".
Form – illustrations, video, layered information
Ruter plans to provide layered information, and is considering, among other things, using illustrations to explain the data flow and where personal data is transferred in the solution.
Read more about design in connection with software development.
We agree that the form has to serve a purpose, and that, for example, illustrations and video should not be used when this does not contribute to making the message easy to understand.
We have also discussed that, in some areas, it may be appropriate to have more than two layers of information. This can, for example, be done when Ruter has to explain more complicated topics, such as the underlying logic in the model or transfers to third countries. At the same time, it is important to limit the use of layers to what is appropriate, so that the information remains easily accessible and clear. For other and simpler topics, such as storage time or contact information, it will not be appropriate to have as many layers. 19
Particular issues relating to requirements for information when obtaining consent
When collecting data for the development of the AI solution, Ruter will use consent as a legal basis. The information provided to the users must therefore be formulated in such a way that consent will be informed. If Ruter uses a different legal basis for the collection of data locally on users' devices during the preparation phase, these special requirements for information will not become applicable until consent for the development of the AI model is to be obtained.
The GDPR does not set any requirements for the form in which the information must be provided. This means that the information can be presented in various ways, including via video or audio recording. When consent is given in a written declaration, Article 7 (2) of the GDRP requires that:
“[...] the request for consent shall be presented in a manner which is clearly distinguishable from [...] other matters, in an intelligible and easily accessible form, using clear and plain language.”
These requirements for form and language are closely associated with the transparency principle in Article 5 (1) (a) of the GDPR. The request for consent must be separate from other information and must be clear and concise. It cannot be inserted into general contractual terms and conditions, and it must be clear that the customer has given consent. The language must be intelligible for a normal customer. It should not be necessary for one to be familiar with difficult foreign words to be able to read the text.
Ruter is working with different proposals for how they can best inform the customer at different levels and obtain consent in the app as shown in the examples below. This can be user tested in order to obtain the best possible insight into how customers understand the message and what they are consenting to.
Examples of how Ruter's requests for consent could generally appear in the Ruter app
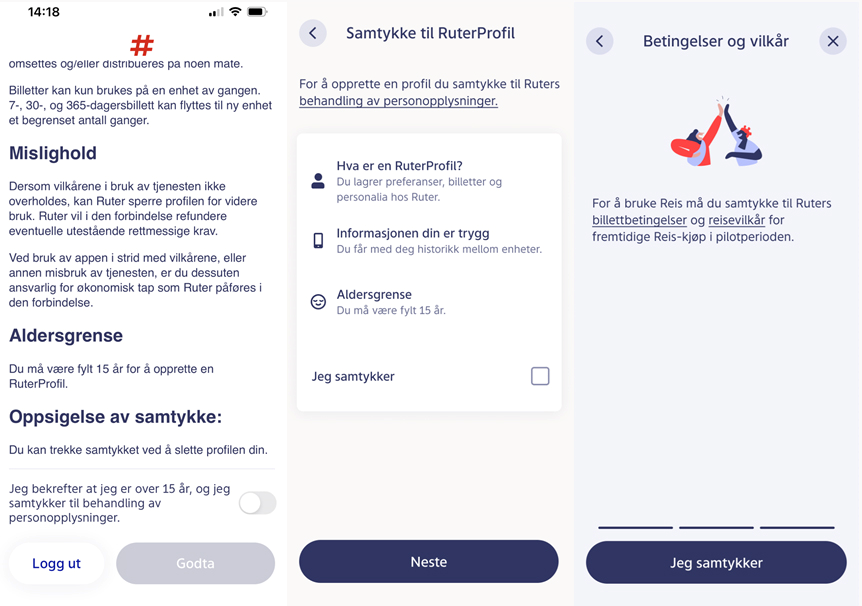
Ruter is planning to obtain consent through a button/tick-box that is displayed on the same page as the information provided to the data subjects in the first layer. The information page will appear in connection with an update of the app. There is also the option of notifying customers if an update is available. The first layer of information needs to satisfy both the minimum requirements for information in Articles 12 and 13 of the GDPR and the minimum requirements for informed consent.
In the sandbox project, the Norwegian Data Protection Authority and Ruter agreed that it is important to provide a simple but sufficiently detailed explanation for consent to be informed. It is crucial that the data subjects understand what they are consenting to. The development of AI can be difficult to understand. The need to provide an adequate explanation must therefore be balanced against the need for the information to be easy to understand.
Ruter has a service that is intended to reach all customers. The information therefore has to be communicated to a broad spectrum of people and it cannot be expected that the customers will have a complete understanding of what an AI model is. In order to understand what one is consenting to, a form of explanation is required.
In addition to information about the actual AI model, it is important that the users understand how their personal data will be processed during the storage and transfer periods. Ruter is considering preparing illustrations to provide a simple and concise description of the technical flow of data. An example of this is the illustration at the start of the report. An intelligible description of the flow of personal data is important for the data subjects to be able to assess whether this is something they wish to consent to. This will enable the data subjects to, for example, make their own assessments of whether they believe the personal data will be protected in a manner that inspires trust.
The special conditions that apply for a child's consent pursuant to Article 8 of the GDPR and Section 5 of the Norwegian Personal Data Act do not apply because Ruter has set an age limit of 15 years for being able to use the Ruter app. However, Ruter still needs to consider the fact that a 15-year-old may, for example, need information to be tailored differently to an 80-year-old.
One method of ensuring that the users actually understand the information is to conduct representative customer surveys. This is something that Ruter plans on doing.