How to explain the use of artificial intelligence?
Transparency is a fundamental principle of GDPR. In addition to being a prerequisite for uncovering errors, discriminatory treatment or other problematic issues, it contributes to increased confidence and places the individual in a position to be able to assert their rights and safeguard their interests.
See GDPR Article 5 (1) (a) and Recital 58.
Transparency and explainability
In connection with AI, the concept of ‘explainability’ is often used, which addresses AI-specific problem issues associated with transparency, which can be said to be a part of the concretising of the principle of transparency. Traditionally, transparency has been about showing how different personal information is used; however, the use of AI requires other methods that can explain complex models in an understandable way.
Explainability is an interesting topic, both because explaining complex systems can be challenging and because the way in which the requirement for transparency is to be implemented in practice will vary from solution to solution. In addition, machine learning models permit explanations that appear radically different than those we are used to, generally based on advanced mathematical and statistical models. This opens the way for an important trade-off between a more correct, technical explanation or a less correct, but more understandable explanation.
In this section of the report, we share evaluations and conclusions from the discussions we held concerning transparency and explainability in NAV's solution for predicting the length of sickness absences. Advisers at NAV offices and the person on sick leave as an individual are the two most central target groups for explanation in this case.
Transparency requirement
Regardless of whether you use artificial intelligence or not there are certain requirements for transparency if you process personal data. Briefly summarised these are:
- The registered person must receive information about how the information will be used, whether the information is obtained from the registered person themselves or from others. (See GDPR Articles 13 and 14.)
- The information must be easily accessible, for example on a web page, and must be written in clear and understandable language. (See GDPR Article 12.)
- The registered person has the right to know whether information is processed about him/her and the right of access to his/her own information. (See GDPR Article 15.)
- It is a fundamental requirement that all processing of personal information shall be carried out in a transparent manner. This means that it is a requirement to assess which transparency initiatives are required in order for the registered person to be able to safeguard his own rights. (See GDPR Article 5.)
In the first bullet point, there is a requirement for information to be provided about how the information will be used. This includes the contact details of the data controller (in this case NAV), the purpose of the processing and which categories of personal data will be processed. This is information that is typically provided in the privacy statement.
Please see more detailed information concerning the requirement for transparency in AI solutions in the report Artificial intelligence and personal privacy (2018)
In regard to artificial intelligence, it may be useful to note the requirement that the underlying logic of the algorithm must be explained. There is a specific requirement to provide “relevant information concerning the underlying logic and the significance and the envisaged consequences of such processing”. It is not necessarily self-evident as to how these requirements should be interpreted. One should strive to ensure that the information given is meaningful, rather than using complicated explanation models based on advanced mathematics and statistics. It is also highlighted in the GDPR’s Recital 58 that technological complexity makes transparency additionally important. The expected consequences should also be exemplified, for example with the help of visualisation of previous outcomes.
It is specified that this should in any event be done in cases of automated decision-making or profiling according to Article 22. Whether information about the logic must be provided if there are no automatic decisions or profiling must be considered from case to case, based on whether it is necessary for the purpose of securing fair and transparent processing.
Automatic, or not?
If processing can be categorised as automated decision-making or profiling according to Article 22, there are additional requirements for transparency. You have, among other rights, the right to know whether you are the subject of automated decision-making, including profiling. There is also a specific requirement that the individual is provided with relevant information concerning the underlying logic and the significance and the envisaged consequences of such processing, as stated above.
Relevant regulations
See the additional requirements for transparency in automated decisions or profiling pursuant to Article 22 in:
However — do you have the right to an individual explanation about how the algorithm reached the decision? The wording of the legislation itself does not state this; however, the GDPR Recital 71 state that the registered person has the right to an explanation of how the model arrived at the result, i.e. how the information has been weighted and evaluated in the specific instances, if one falls within the scope of Article 22. The GDPR Recital 60 also state that the registered person should “be informed of the existence of profiling and the consequences of such profiling”. The recitals themselves are not legally binding and do not of themselves grant the right to an individual explanation.
The requirement for transparency does not necessarily mean that the source code must be made available; however, the explanation must enable the registered person to understand why a decision was what it was. This applies where the decision falls within the scope of Article 22 concerning automated individual decision-making. One can also imagine circumstances where the fairness and transparency principle places higher demands on explanation, for example in profiling that does not comply with the conditions of Article 22, but where sound reasons indicate that the registered person should receive such information.
A meaningful explanation will depend not only on technical and legal requirements, but also linguistic and design-related considerations. An evaluation must also be performed of which target group the explanation is aimed at—something that may mean a difference for advisers and users. The practical application itself of the explanation model in advisers’ daily working day may also mean that trust and the sense that the adviser is receiving a meaningful explanation may vary, in that explanations provided appear to be standardised and therefore offer little guidance over time. Social factors such as trust in the enterprise, the significance of the decision and trust in AI systems in general may also influence the experience of a meaningful explanation.
A key question for NAV has been whether the prediction model for the length of sickness absence is an automated decision and therefore invokes these extra requirements, or not. In this case, there is little doubt that the prediction model does not constitute fully automated processing. The prediction will be one of several information elements that an adviser must evaluate before a decision is made.
However, there are reasons for information to be provided about the logic and mode of operation in models that are not fully automated. The prediction model carries out profiling, and a meaningful explanation contributes to building trust and is an expression of responsibility. Additionally, a meaningful explanation will put an adviser in a better position to evaluate how much weight they shall place on the recommendation generated by the algorithm.
GDPR definition of profiling
‘profiling’ means any form of automated processing of personal data consisting of the use of personal data to evaluate certain personal aspects relating to a natural person, in particular to analyse or predict aspects concerning that natural person’s performance at work, economic situation, health, personal preferences, interests, reliability, behaviour, location or movements;
(Art. 4 GDPR)
Regardless of whether this concerns fully automated decision-making or not, the data processor is required to provide sufficient information so that the user has the information necessary to safeguard his/her rights. NAV's central role in public administration leads to an asymmetric power relationship between user and government body, which is also an argument in favour of striving for as meaningful an explanation as possible, despite the fact that the model is not fully automated.
Can we trust the algorithm?
Good explanations of the algorithm and its predictions increase trust in the systems on the part of its users, which is fundamental in achieving the desired value. The several thousand NAV employees that work in user guidance therefore play a decisive role.
The system that predicts the length of sickness absence is a decision-making support system; but what happens if the system in practical use becomes a decision-making system? A NAV adviser reviews many cases in the course of a normal working day. If it appears that the algorithm provides consistently sound recommendations, it can indeed be tempting to always follow these recommendations. The adviser might perhaps believe that the algorithm holds so much data that it knows best, so why should the recommendation not be followed? How easy is it for a recently hired employee not to follow the recommendation of the algorithm?
Or, what if the adviser believes that the algorithm is generating strange recommendations and does not trust them? A consequence of this would be that the adviser does not consistently use this as decision-making support. This will also be unfortunate, as the entire intention of the solution is to help advisers to make good decisions, so that invitations to dialogue meetings are more often appropriate. Ideally, this type of model will reduce arbitrary variations among advisers and lead to more uniform practice, in addition to reducing costs.
In the sandbox we discussed the risk that an adviser will rely too much or too little on the decision-making support system and how to ensure that the system is experienced as providing genuine support for the adviser and is used in a sound and correct manner. That an adviser must receive proper training and instruction in how the algorithm functions and is used, and a meaningful explanation in individual cases is important in order to reduce the risk of “automation by stealth”, or that it is not included in the evaluation at all. When a NAV adviser understands the construction of the model, its mode of operation and behaviour, it will be simpler to evaluate the prediction on an independent and secure basis. Additionally, the explanation can help the adviser to uncover discrimination, undesirable differentiation and errors. In such a case, an explanation associated with individual decision-making will be supplemented with information associated with the outcome for certain naturally comparable groups.
Explanation of the model:
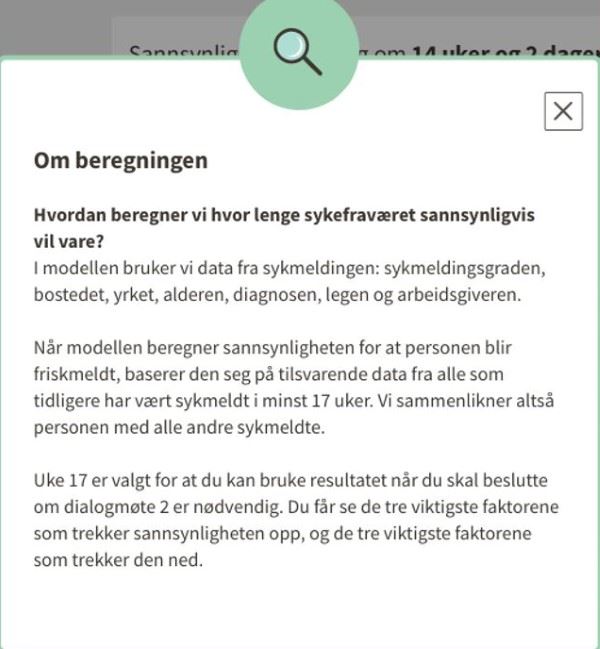
This screenshot shows an example of how a general explanation of the operation of the model can appear for an adviser using the system.
It includes the data used in the model, explains that the model is based on similar data from everyone who has previously been on sick leave for at least 17 weeks, and it explains that the supervisor will now see the three most important factors that increase the probability, and the three most important which reduces it.
What does a meaningful explanation look like?
An issue we have discussed in the sandbox is how a meaningful explanation would look in practice in NAV's case. The target group for transparency in the solution are those on sick leave and NAV advisers. The explanations are both global, i.e. at a system level, and local outcome explanations. The two different levels will therefore have partially different target groups, and differing requirements apply as to how they are organised.
NAV wishes to provide information in advance of processing that the user has the right to protest entirely against that a prediction will be made based on profiling at all. They also wish to inform about how the model is constructed and which variables are incorporated. NAV also considers informing the individual user about the most important factors that extend the predicted sickness absence period and the most important factors that reduce it.
A meaningful explanation does not only depend on technical and legal requirements, but also linguistic and design-related considerations. The explanation must be adapted to the specific target group. For example, NAV advisers require explanations that can be used in practice in a hectic working day. NAV must therefore balance and make a trade-off between depth and simplification that make it possible to use the explanation. Moreover, the explanation must also be integrated with other information to which the adviser has access. A specific example is that NAV cannot present information about how 100 variables have contributed to a prediction. NAV must group these together and make a selection. Particular vigilance is required if the explanation is aimed at children or vulnerable groups. NAV’s model may include several special categories of personal information about vulnerable groups, and NAV must therefore consider adapting language, content and form based on this.
Information concerning data:
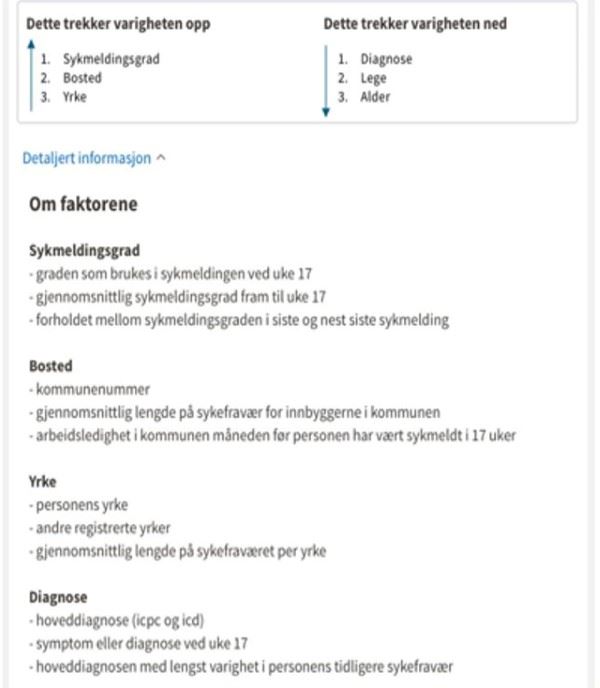
This is how NAV envisages that their advisors can be presented with which data will be used and applied as a basis, in which manner, in the model.
Here, the factors that increase or decrease the probability of permanent sick leave are presented, together with a key word explanation of what is included in the factors.
In regard to the advisers, NAV plans to explain how the model works in general terms and to describe how the results produced by the model should be used in case processing routines. In addition, advisers will receive explanations at an individual case level as well as information components the model has learned from, as part of the information basis to make the final decision as to whether or not a user will be invited to a dialogue meeting. The prediction will constitute one of several elements that are available to the adviser, including the information on which an adviser bases a decision at present.
In addition to the two main target groups (users and advisers) discussed here, NAV has identified the business side/management, those responsible for the model and supervisory authorities as other target groups that will have a need for, and the right to, an explanation of how the algorithm functions.
NAV wishes to shoulder its share of the responsibility in regard to transparency around the use of algorithms. One possible initiative being discussed is to provide general information on how NAV wishes to utilise artificial intelligence. NAV also seeks to contribute to the broad dissemination of information and an informed debate about the use of artificial intelligence through the media. A final measure is to inform and involve a user panel in advance of, and during, the development of services based on artificial intelligence.