Measures to reduce algorithmic bias
In the sandbox project, we have discussed how Ahus can reduce algorithmic bias, both in the model itself through technical measures, and in correcting for algorithmic bias after the algorithm has been implemented, through organisational measures.
It is pointed out in recital 71 of the GDPR that fair processing of personal data entails “implement[ing] technical and organisational measures appropriate to ensure, in particular, that factors which result in inaccuracies in personal data are corrected and the risk of errors is minimised, |and] secur[ing] personal data in a manner that takes account of the potential risks involved for the interests and rights of the data subject and that prevents, inter alia, discriminatory effects on natural persons (...)”.
Comment from the Equality and Anti-Discrimination Ombud:
A lack of precision in the algorithm for defined patient groups does not necessarily mean that Ahus, as a legal entity, is discriminatory in its practices. The determining factor under the Equality and Anti-Discrimination Act is that persons protected from discrimination are not “treated worse than others”, see Section 7.
The determining factor in this context is whether the differential treatment leads to “harm or detrimental effects for the person subjected to the differential treatment, e.g. by the differential treatment causing the person to lose benefits, suffer an economic loss or have fewer options compared to others in a similar situation. There must be a specific and direct effect on specific natural persons.
(Prop. 81 L (2016-2017), Ch. 30, comment to Section 7)
The Ombud is of the opinion that Ahus can compensate for algorithmic bias by supplementing with other medical methods in their examination of patient groups for which the algorithm produces less accurate predictions. The determining factor for achieving equal treatment for all is to know which patient groups the algorithm is less accurate for, and to implement measures to ensure that these patients are afforded the same level of health care as other groups.
Some general examples of technical measures include pseudonymisation, encryption or anonymisation of personal data, to minimise the intrusion on the data subject’s privacy. Organisational measures include the introduction and implementation of procedures and practices that ensure compliance with laws and regulations.
Three types of measures
In this project, we have primarily focused on three different types of measures:
- Analysing and checking the algorithm’s data sources (technical measure)
- Establishing procedures for training health personnel in the use of the decision-support system (organisational measure)
- Establishing a monitoring mechanism for post-training (technical measure)
Technical measure: Analysing and checking the algorithm’s data sources
The Norwegian National Strategy for AI highlights distortions in the underlying data as a particular obstacle to inclusion and equitable treatment. This is explained as follows: “datasets used to train AI systems may contain historic distortions, be incomplete or incorrect. Poor data quality and errors in the data source for EKG AI will therefore be embedded in and reinforced by the algorithm and may lead to incorrect and discriminatory results. Poor data quality can, for example, be caused by repeated misdiagnoses by health personnel. In order for the algorithm to be able to find an accurate pattern in the data set, the information must be consistent and correspond to facts.
Ahus has used historical health data with a statistical correlation with the risk of heart failure. The data source for the algorithm includes results from approx. 100,000 electrocardiograms (EKGs), ICD-10 diagnosis codes for heart failure and information about the heart’s ability to pump blood. This information is taken from the cardiology system and the patient file system DIPS at Ahus.
In our discussion, we have focused especially on two different methods for minimising algorithmic bias in the data source:
- Method 1 does not introduce new data to the algorithm; instead, under-represented patient groups are “inflated” in the data source. The challenge with this method is that it yields better accuracy for some patient groups, but would lead to less accurate results for patients in the majority group.
- Method 2 adds more data points (labels) to the algorithm for the under-represented patient group. With this approach, one would have to accept a higher degree of discrimination in an initial phase, but over time, the algorithm will become more accurate. The challenge with this method is that one does not necessarily have the information needed to correct the bias that has been identified.
Only after a representation bias in the algorithm has been documented is it possible to implement corrective measures. A central focus of our discussions have been to identify which groups are under-represented in the algorithm’s data source. In particular, we have looked into representation of gender and ethnicity, as there are examples of other algorithms that turned out to discriminate on the basis of these factors.
Read Wired.com's article on discrimination against ethnic minorities in healthcare and/or Reuter's article on Amazon's recruitment algorithm, which systematically discriminated against female applicants.
Position of the Equality and Anti-Discrimination Ombud:
In connection with the Ahus EKG AI project, the Ombud’s position is that the greatest potential for discrimination is tied to representation bias in the data source. Research literature on heart failure (see under) points out that heart rates vary for different ethnicities. This means that ethnic minorities could have EKG curves that differ from the majority population in Norway, and this should be accounted for, both in the development and application of the algorithm.
Read a research article on the effect of ethnicity on athletes' ECG at mdpi.com
Information about ethnicity is not recorded in the patient file, nor is this information available in any other national sources. This leaves Ahus with limited options for checking whether the algorithm is less accurate for ethnic minorities than it is for the majority population. In order for Ahus to gain access to this information, they must conduct a clinical trial based on voluntary collection of data, to verify the algorithm’s predictions for this patient group. In the sandbox project, Ahus has argued for a need to register information about the patients’ genetic origin to ensure that they provide safe health services to all. Registration of ethnicity is a sensitive topic, and whether, and if so, how, this can be handled in practice, will be for national authorities to assess.
Clinical trials
According to Helsenorge.no, clinical trials are defined as "research into the effect of new treatment methods, and into whether the side effects are acceptable."
Information about the patient’s gender is part of the EKG AI data source, categorised as “man” and “woman”. There is no data on whether the algorithm is less accurate for patients who do not identify as either a man or a woman, or patients who have had gender reassignment surgery. If so, a clinical trial must be conducted to check for this. The prevalence of first-time cases of heart failure has been consistently higher among men than women. According to Ahus, different types of heart failure require different treatments and follow-up, and women are more represented in one of the three types of heart failure. As a result of women being historically under-represented in medical research, there is a general risk that women will have less accurate results than men when the algorithm has been trained on historical health data. Ahus can confirm, however, that there is a robust data source for female heart failure patients in EKG AI, and that it is therefore unlikely that EKG AI would discriminate against women.
If the algorithm is sold to other actors in or outside of Norway in the future, there is a risk of the data source not accurately reflecting the new patient groups the algorithm is asked to give predictions about. To maintain a high level of accuracy, the algorithm will need post-training on new, localised patient data. This is covered in measure 3 “Monitoring mechanism for post-training”.
Organisational measure: Algorithm meets health personnel
Until now, development of the decision-support tool EKG AI has taken place in a lab. A clinical trial is necessary to verify the algorithm’s accuracy and predictions on real data before it is implemented in a clinical setting. In order to optimise how the decision-support tool functions, the result of the algorithm’s calculations must be presented to health personnel in a way that makes the prediction work as intended, i.e. as a decision-support tool for more efficient diagnosis of heart failure than what we currently have. The result must be available to the recipient immediately, health personnel must be able to interpret the result and apply it correctly. The overall goal is for EKG AI to be more accurate and precise than health personnel are able to be on their own, so that it contributes to improved and more efficient health services.
Article 22 of the GDPR prohibits decisions based solely on automated data processing. In order for the prohibition to apply, the decision must be fully automated, without any human involvement. EKG AI will be used as a decision-support tool, and the prohibition of Article 22 therefore does not apply. Good information and training of health personnel about how to use the decision-support tool will ensure actual human intervention is involved in the decision-making process, and will also reduce the risk of health personnel relying indiscriminately on the algorithm’s predictions in practice.
Algorithms are advanced technical systems, and health personnel must know how they work and be trained in how to use them. This entails, primarily, that health personnel receive an explanation on how to use the algorithm, but also that they be informed about risk factors and margins of error in the algorithm’s predictions. Health personnel must be able to understand how the algorithm works and the background for its predictions, to prevent mistrust in the tool. Insight into and an understanding of how the model works is also essential to enable health personnel to independently assess the predictions. If, in the future, it is determined that the algorithm’s accuracy varies for different patient groups, this must also be communicated to health personnel. Training can include information about discrimination and how health personnel need to keep this in mind.
Health personnel will only use EKG AI if there is a suspicion that the patient may have heart failure. The result from the algorithm is sent back to the EKG archive (ComPACS) at Ahus. The result is displayed to health personnel in a text format in a field next to the patient’s EKG reading. Ahus is aware of the risk of notification fatigue in health personnel if too many warnings and too much information appears at the same time. As EKG AI will be used in emergency situations, it is especially important that the information provided is clear and precise. The sandbox project has therefore discussed different ways the prediction can be presented. The prediction can be presented as a percentage, as categories of either “low”, “medium” or “high”, or a limit could be defined for emergency/non-emergency follow-up. In this process, it will be beneficial to involve health personnel to get insight into what the best way of presenting the results could be. Ahus will explore how to specifically present the prediction in a clinical trial. In a trial, it will be possible to try out the decision support tool in practice on a limited number of patient and with selected health personnel.
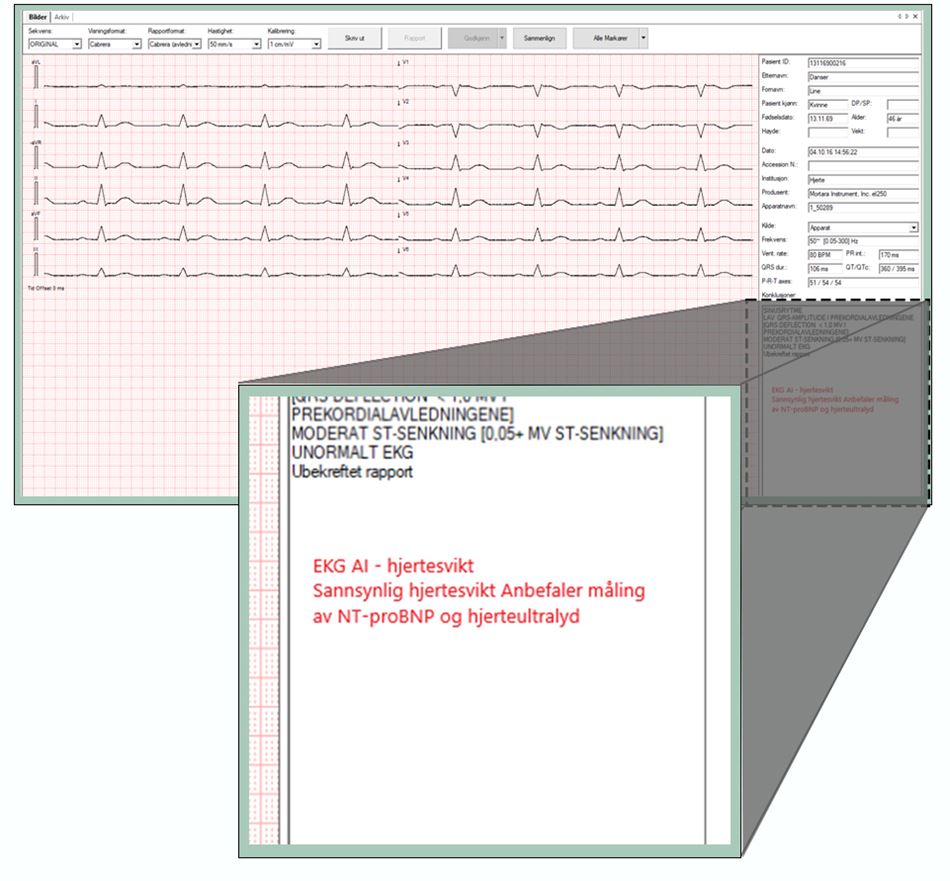
This illustration is showing how the results from EKG AI can be presented to health personnel.
As a result of the results from the algorithm being stored in the EKG archive (ComPACS), there is a risk that the result will not be discovered by health personnel immediately. Ahus will therefore consider alternative means of notification, e.g. through monitors at the hospital or by sending a message to the health personnel’s work phones. However, this type of notification requires better infrastructure than is currently available at Ahus.
In connection with health personnel training, Ahus will establish procedures and protocols for use of the tool. When the algorithm is developed further, it would be natural for procedures, protocols and the training itself to also be updated. Ahus has an existing non-conformity reporting system, where health personnel report non-conformities that can be used to improve the algorithm in the future.
Technical measure: Monitoring mechanism for post-training
Over time and with societal changes, EKG AI’s predictions will become less accurate. Lower accuracy will occur naturally when a population changes. As an example, new patient groups may emerge, due to the arrival of refugees from a country the algorithm has no data for. When the accuracy is no longer satisfactory, post-training of the algorithm will be required. Post-training entails training with new data, testing and validation of the algorithm.
The EKG AI algorithm does not have continuous post-training, which means that its accuracy will not automatically adjust to future changes. Instead, Ahus plans to implement a monitoring mechanism, designed to be triggered when the algorithm’s accuracy falls below a pre-defined limit, and the algorithm needs post-training. In order to validate such a limit value, Ahus will conduct a clinical trial while algorithm is being tested in a clinical setting.
In practice, the monitoring mechanism will compare the algorithm’s prediction with the diagnosis health personnel set for the patient. This way, it will be possible to assess the degree to which the algorithm’s prediction is accurate for the patient’s real-life medical condition. The limit value for accuracy will then determine when and if post-training of the algorithm is required.