The content of the fairness principle is dynamic, which means it changes over time, in line with society’s interpretation. The European Data Protection Board (EDPB) specifies, in its guidelines on data protection by design and by default, that the fairness principle includes non-discrimination, the expectations of the data subject, the wider ethical impact of the processing and respect for the data subject’s rights and freedoms. In other words, the fairness principle has a wide scope of application.
See Guidelines 4/2019 on Article 25 Data Protection by Design and by Default | European Data Protection Board (europa.eu)
A similar description can be found in the recitals of the GDPR, which emphasises that this principle entails that all processing of personal data must be carried out with respect for the data subject’s rights and freedoms, take into account the reasonable expectations of the data subject for what the data will be used for. Transparency in processing is therefore closely linked to the fairness principle. Adequate information is a key factor in making sure the processing is predictable for the data subject and in enabling the data subject to protect their right to fair processing of their personal data. This final report does not discuss issues related to the information requirement, but we refer to the exit report for the Helse Bergen sandbox project, which does.
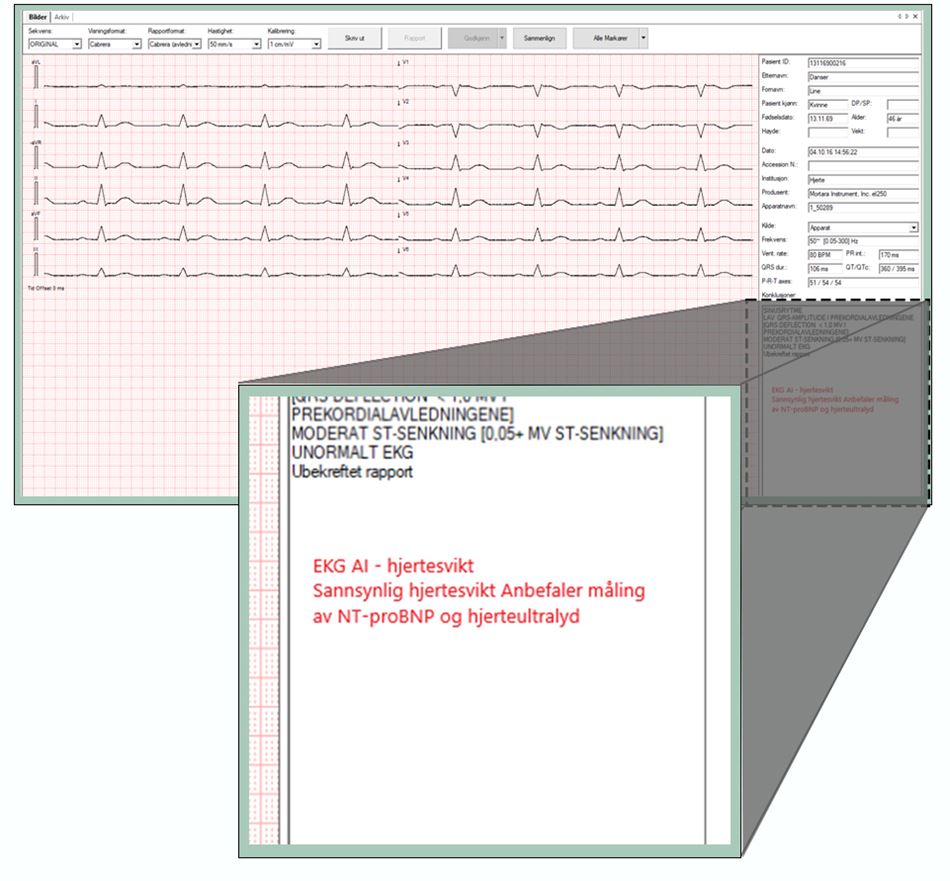
The recitals of the GDPR further specifies that the controller shall prevent discrimination of natural persons on basis of racial or ethnic origin, political opinion, religion or beliefs, trade union membership, genetic or health status or sexual orientation. The recitals is not legally binding, but can be used as a guide in interpreting the provisions of the GDPR. In the Ahus project, we have considered, among other things, whether the EKG AI algorithm will give all patients equal access and equally good health services, regardless of whether the patient is male or female, or whether the patient has a different ethnic background than the majority of the population.
The fairness principle is a central element in several other pieces of legislation, including various human rights provisions and the Equality and Anti-Discrimination Act. These are relevant for the interpretation of fairness, as their requirements are sometimes more stringent and specific than the GDPR.
What does the Equality and Anti-Discrimination Act say?
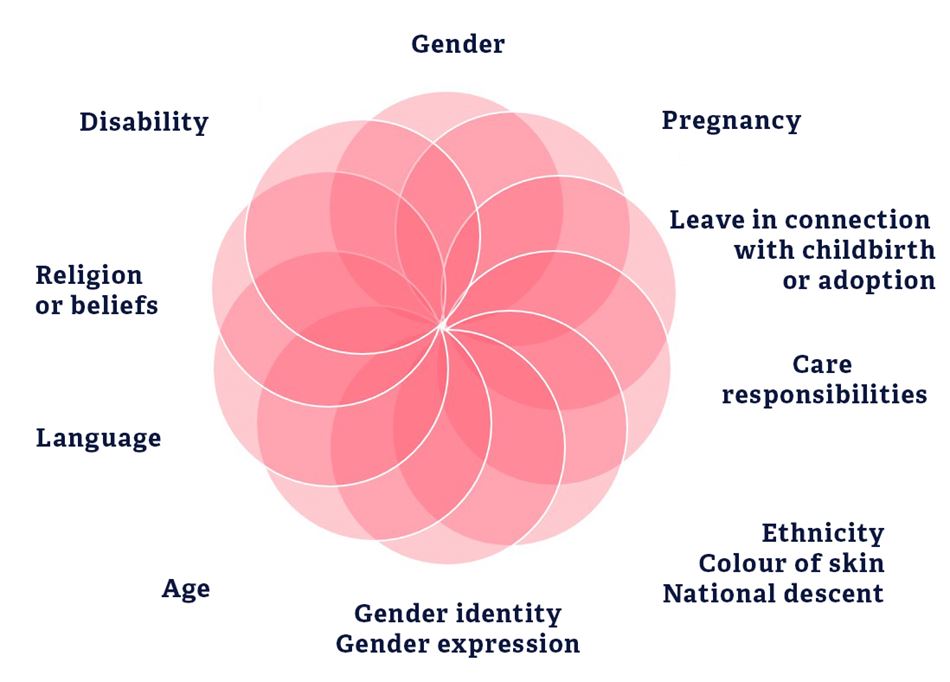
The Equality and Anti-Discrimination Act prohibits discrimination on the basis of “gender, pregnancy, leave in connection with childbirth or adoption, care responsibilities, ethnicity, religion, belief, disability, sexual orientation, gender identity, gender expression, age or any combinations of these factors, see Section 6.
Definition of ethnicity:
It follows from the provision that the term “ethnicity” refers to, among other things, national origin, heritage, skin colour and language.
Discrimination is defined as unfair differential treatment and may be “direct” or “indirect”, see Sections 7 and 8.
Direct differential treatment means that a person protected from discrimination is treated worse than other comparable persons, see Section 7, whereas indirect differential treatment means that an apparently neutral provision, condition or practice leads to a person protected from discrimination being put in a worse position than others, see Section 8. Indirect discrimination may, for example, arise by an apparently neutral algorithm being used indiscriminately for all patient groups. As a result of the prevalence of heart failure being consistently higher among men than women, female cardiac patients would be less represented in the data source, which could mean the predictions for women may be less accurate.
Read more about gender statistics for heart failure in the Norwegian Cardiovascular Disease Registry's report for 2012-2016 at fhi.no (pdf - in Norwegian)
Both direct and indirect discrimination requires a causal link between the differential treatment and the basis of discrimination, i.e. that a person is put in a worse position due to their gender, age, disability, ethnicity, etc.
Furthermore, public authorities have a duty to act, pursuant to Section 24 of the Act, by making active, targeted and systematic efforts to promote equality and prevent discrimination. The sandbox project may be used as an example of a project with the intention of promoting equality and preventing discrimination by implementing specific measures in the public health services.
Fairness as an ethical principle
Fairness is also an ethical principle, which means that ethical considerations are central in the interpretation, and application, of the fairness principle in the GDPR. “Ethics guidelines for trustworthy AI”, a report prepared by an expert group appointed by the European Commission, mentions three main principles for responsible artificial intelligence: lawful, ethical and robust artificial intelligence. The same principles are reflected in the Norwegian Government’s National Strategy for Artificial Intelligence from 2020.
In ethics, one considers how one should behave and act to minimise the ethical consequences of using artificial intelligence. While something may be within the law in the legal sense, one may still ask whether that something is ethical. Ethical reflections should be encouraged in all stages of the algorithm's life – in development, in practice, and in the post-training stage.
In ethics, one wants to answer questions about “what is good and bad, good and evil, right or wrong, or fair and equal treatment for all”? An ethical approach to the EKG AI project would be to ask whether the algorithm will give equally good predictions for all patients. With increased use of algorithms in clinical settings in the future, it will be relevant to ask whether the general benefits to using artificial intelligence will truly benefit all patients.
Algorithmic bias
Artificial intelligence
In the Norwegian Government’s National Strategy for Artificial Intelligence, artificial intelligence was defined as “systems [that] act in the physical or digital dimension by perceiving their environment, processing and interpreting information and deciding the best action(s) to take to achieve the given goal. Some AI systems can adapt their behaviour by analysing how the environment is affected by their previous actions.” The term algorithm is often used about the code in a system, i.e. the recipe for what the system is finding a solution for.
All solutions based on code will, naturally, contain errors or inaccuracies. This is true for both highly advanced systems and simpler solutions, but the more complex the code, the greater the risk of errors. In machine-learning solutions, errors will likely result in the algorithm's predictions being less accurate or incorrect. Errors that systematically produce less accurate, or incorrect, predictions for some groups will be examples of what we call algorithmic bias.
When two patients have virtually identical health needs, they should receive equally comprehensive health care services – regardless of ethnicity, gender, disability, sexual orientation, etc. However, if an algorithm recommends different levels of help, there may be reason to suspect some form of discrimination.
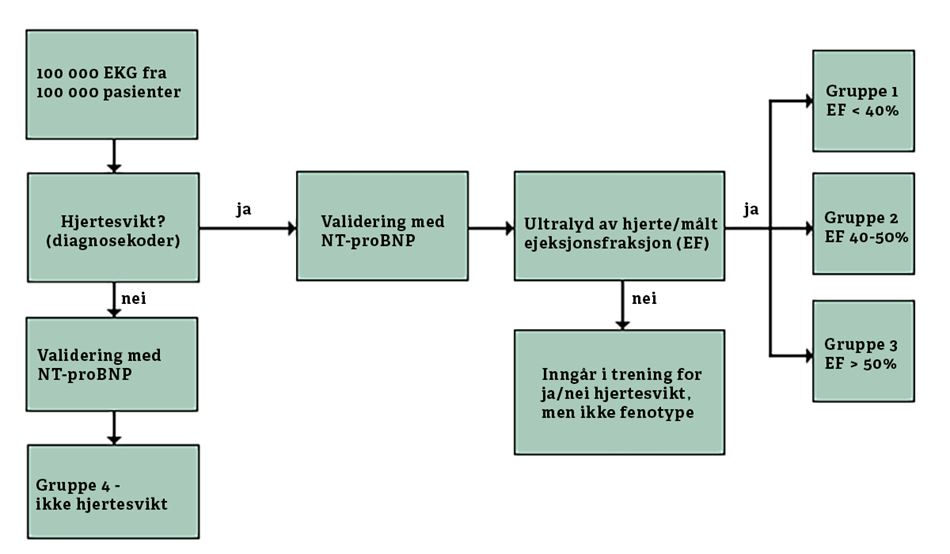
There are many potential reasons for algorithmic bias, and the cause of it is often complex. In this project, we have focused on four causes for algorithmic bias.
This is because these four causes have been most relevant for our project, but these are also common for artificial intelligence in general. The description and illustration below are based on a presentation in the British Medical Journal, which focuses on algorithmic bias in the health sector. We want to emphasise that several of the causes may lead to the same bias, and that there is some overlap between the different causes.
Feel free to read the article "Bias in AI" on aimultiple.com.
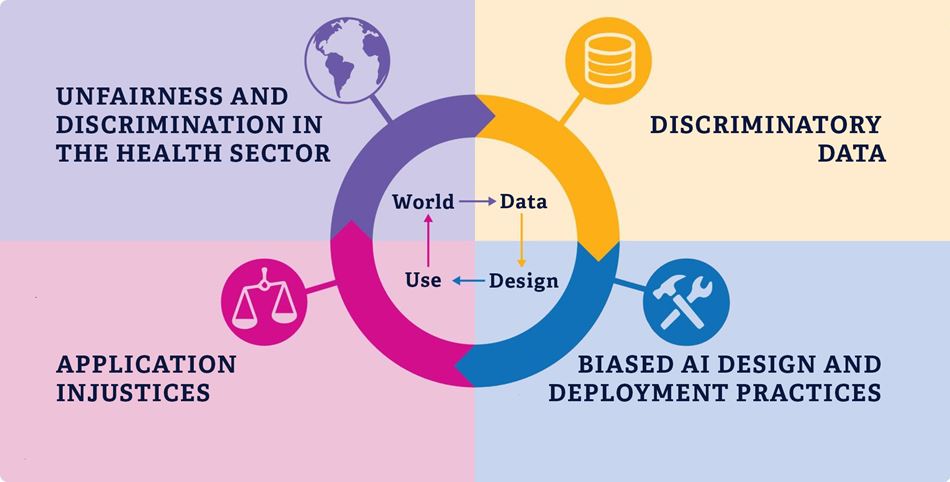
1 Unfairness and discrimination in the health sector
A machine learning algorithm makes predictions based on the statistical probability of certain outcomes. The statistics will be based on historical data, which reflects reality, including existing unfairness and discrimination in the health sector. This includes exclusionary systems, prejudiced health personnel or varying access to health services. This is perpetuated and reinforced in the algorithm.
2 Bias in the data source
Unfairness in society will be reflected in the data sources fed to the algorithm during training. If there is bias in the facts, the algorithm’s predictions will reflect this bias. If the training data is not sufficiently diverse, the algorithm will not be able to give accurate predictions for under-represented individuals or groups. This could, among other things, happen when different population groups have different levels of access to health services for socioeconomic reasons.
3 Bias in design and production practices
Algorithmic bias may also arise from the developers’ biases and choices made in the development stage. One reason for this could be that the developers either are not aware of or do not understand the potential discriminatory outcomes of the design choices they make. Another reason could be that no systems exist to identify unintended discrimination when the algorithm is used.
4 Unfairness in application
An algorithm with hidden bias will reinforce an already discriminatory practice. In cases where the algorithm learns from its own predictions, this bias will be further reinforced in the algorithm. Using an algorithm programmed with the wrong purpose could also lead to discrimination in practice, for example when the purpose of identifying a person’s health needs is justified by how much money that person has spent on health services.