In the Simplifai sandbox project, we have explored what leeway exists for the use of personal data in a decision-support tool based on machine learning.
The GDPR applies with equal force in 30 countries in Europe. In addition, Norway has special rules on privacy, including privacy in working life. These special rules are laid down in Working Environment Regulations and are intended to protect workers from unnecessarily invasive monitoring or control.
How did we approach the assessment?
Initially, the sandbox project discussed whether we should base our assessment on full automation of DAM or on DAM as a decision-support tool. While automation would have the greatest effect, the risk of violating data protection legislation would also be higher, in that content from personal inboxes would be entered directly into the public record. The project decided to focus on DAM as a decision-support tool.
The project organized two workshops focused on lawfulness. As preparation for these workshops, Simplifai provided information about the technical solutions and the purpose of the different modules/bots. In addition, NVE expressed its views on, among other things, the purposes of the processing performed by the modules and the legal basis the directorate believed it had for implementing the solution. Based on these thorough preparations, the Data Protection Authority outlined a framework for use, continual learning and potential measures for making DAM more data protection-friendly.
We opted to split the legal basis issue into phases: (1) the use phase, where the algorithmic model is used in the administrative process, and (2) the continual learning phase, where the algorithmic model is improved.
Simplifai came to the sandbox with an already-developed tool. The project was limited to the question of whether Simplifai had a legal basis for developing DAM.
Legal basis for the use phase
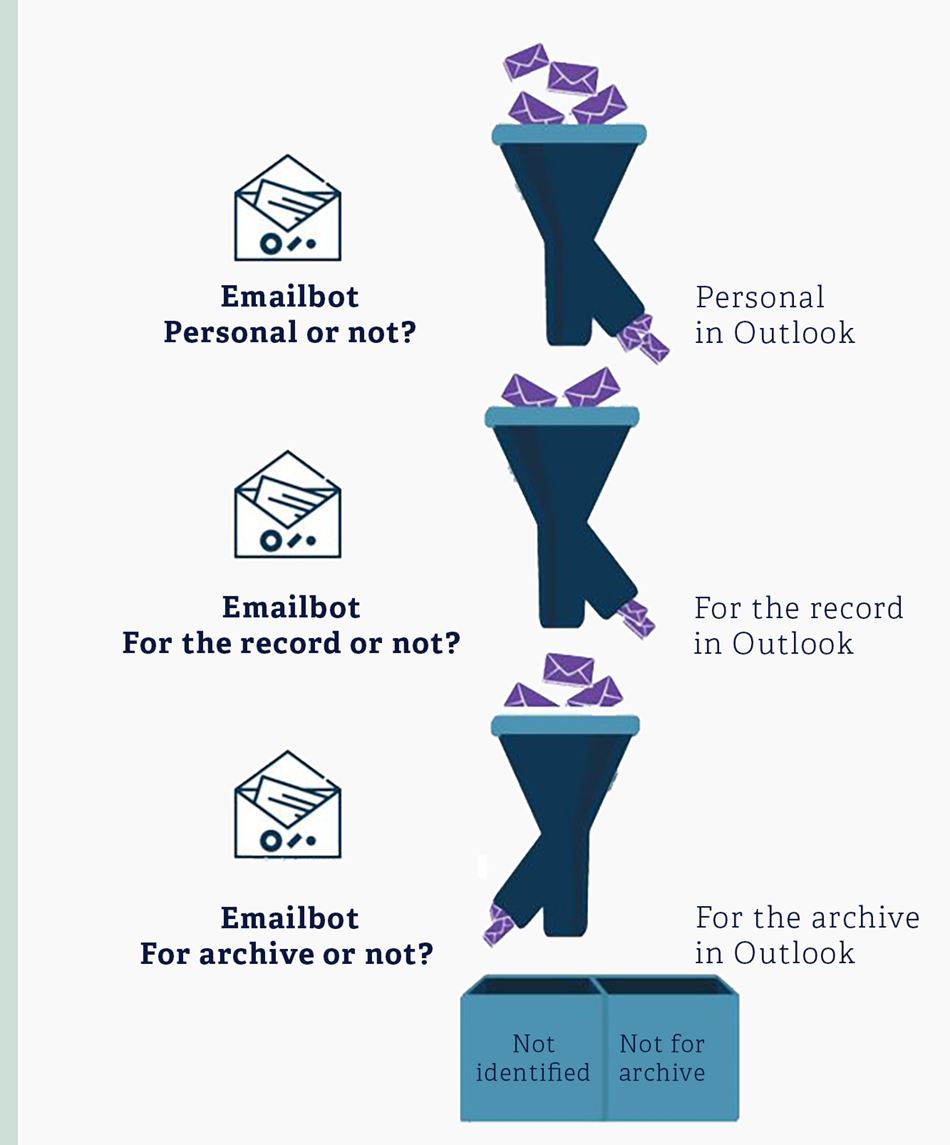
In this phase, DAM is being used as a decision-support tool and serves as a guide for administrators when they are considering whether an e-mail is personal in nature, whether it should be entered into the record and whether it should be archived.
The processing of personal data in record-keeping and archiving currently takes place pursuant to Article 6 (1) (c): “processing is necessary for compliance with a legal obligation to which the controller is subject”.
The legal obligation to maintain an archive is laid down in Section 6 of the Archive Act and Sections 9 and 10 of the Regulations Relating to Public Archives. In addition, the obligation to keep records is laid down in Section 10 of the Freedom of Information Act.
The sandbox project recommends that public bodies base their processing on Article 6 (1) (c) even when using digital tools, such as DAM, to make the archival process more efficient and systematic.
Legal basis for the continual learning phase
The ability of artificial intelligence to learn is a major technological breakthrough. When the algorithm learns through being used, we call this continual learning. The inference (i.e. the result of the algorithm being used on a new data source) is included in the algorithm, which means the tool is dynamically adjusted to become more accurate.
Continual learning can be challenging in terms of data protection law. Even if there is a legal basis for using artificial intelligence for archival purposes, such as processing being necessary to comply with a legal obligation, this does not necessarily mean that there is a legal basis for continual learning of the algorithm.
Article 6 (1) of the GDPR lists six alternative conditions that may provide a legal basis for the processing of personal data. The alternatives most relevant in this case are the conditions found in (c) and (e):
- Processing is necessary for compliance with a legal obligation (c).
- Processing is necessary for the performance of a task carried out in the public interest (e).
In both cases, the GDPR requires statutory authority for the processing in other legislation, see Article 6 (3).
The current Archive Act includes no wording to indicate that e-mails or other material with archival value can be used in the further development of machine-learning systems or other digital tools. DAM would be on firm ground if the Archive Act explicitly provided, that material processed in connection with archival obligations may also be used to improve or further develop digital tools. Even so, continual learning may be considered as a consequence of using the tool, thus establishing a legal basis pursuant to Article 6 (1) (c), as in the use phase.
For society, there is a clear need to improve the efficiency of the archival process and increase associated legal protections. Deciding how access to archive material used in the development of machine learning should be handled, is a matter for legislators. The Data Protection Authority has seen examples where some organizations are authorized to use collected data in the development of IT systems, see Section 45 b of the Act Relating to the Norwegian Public Service Pension Fund.
One way to approach this problem is to design the algorithm in such a way that the inference does not contain any personal data. In this case, the GDPR would not apply, and the algorithm can be trained without restrictions. Another option, if the inference does contain personal data, is to anonymize the data before the algorithm is set to engage in continual learning. Then it would no longer be personal data, and the model can be trained without needing a legal basis.
Another option could be to enable each DAM-user to turn the algorithm's continual learning capability on or off, either in general or with the option to exempt individual e-mails from inference. This could also be positive in terms of transparency concerning how the tool processes personal data, and could help ensure personal e-mails, etc., are not included in the training. One side effect of this approach, however, may be that the underlying data could reinforce an incorrect archival practice.
Is the processing of special categories of personal data lawful?
In the inbox of an administrator in NVE, DAM could find information from the local trade union as well as an e-mail to the boss about illness. Some employees may also use their work e-mail for private correspondence. In these e-mails, DAM may find information about the administrator’s religion and sexual orientation, for example. All of these categories are considered special categories of personal data, see Article 9 of the GDPR. The processing of these categories of personal data is only permitted if the conditions set out in Article 9 (2) have been met.
The sandbox presumes that the condition of “processing [being] necessary for reasons of substantial public interest”, see Article (2) (g), would apply to NVE’s use of DAM. This is reflective of the preparatory works to the NAV Act, where the ministry assumes that efficient processing by the Labour and Welfare Administration and the Norwegian Public Service Pension Fund would be covered by a “substantial public interest”, as laid down in Article 9 (2) (g).
Another key part of this condition is that the processing must be “proportionate” to the aim pursued. In its assessment of proportionality, the sandbox has emphasized that the suggestion will be limited to the administrator only, and that the impact on privacy will therefore be limited. In addition, we recommend establishing guidelines that prohibit or limit the use of the organization’s e-mail address for private purposes, in order to limit the extent of personal e-mails being processed by the solution.
Prohibition against monitoring, see the Email Monitoring Regulations
So far, we have focused on the GDPR. It is, however, also relevant to consider DAM in relation to the Email Monitoring Regulations and their prohibition on “monitoring the employee’s use of electronic equipment, including use of the Internet” (Section 2 (2)).
See the Email Monitoring Regulations (external page)
So it may be lawful for an employer to implement DAM, provided its use does not entail monitoring the employees’ activities. Could the implementation of DAM be considered monitoring of the employees’ use of electronic equipment?
What counts as “monitoring” is not defined in more detail in the regulations. The preparatory works of similar regulations in the previous act highlight that the measure must have a certain duration or take place repeatedly. Monitoring differs from isolated incidents of access, which is permitted in several circumstances. The preparatory works also emphasise that it is not solely a question of whether the purpose is to monitor. The employer must also attach weight to the question of whether the employee may perceive the situation as monitoring.
Past decisions by the Data Protection Authority are not conclusive with regard to whether the employer is required to actually see the personal data for it to count as monitoring. Monitoring is a broad term, and a natural linguistic understanding of the term may entail that collection and systematization are also affected by the prohibition. The fact that the provision is aimed at the employer's monitoring indicates that the employer must, at the very least, be able to access the data concerning the employees in order to be subject to the prohibition. This was the sandbox’s position in the project with Secure Practice as well.
See the exit report from the Secure Practice sandbox project.
After discussions in the sandbox project, there was a consensus that the prohibition on monitoring would not extend to the use of DAM for decision support. We have emphasized that the solution merely makes a suggestion in the administrator’s inbox, and that the information about the categories does not go any further.
In addition, the sandbox project recommends that technical and legal measures be implemented to prevent the employer from having access to the information collected by the solution about the individual employees. One such measure could be to implement a rule that prohibits or limits the use of the organization’s e-mail addresses for private purposes, as mentioned in the section on special categories of personal data.